See the Basics: Llama 3 技术报告精读

这篇 Llama 3 报告精读,最开始其实是因为参加考核才决定仔细研究的。但当时作为萌新的我在读的时候,发现里面有很多值得深挖的技术细节,于是顺带着补充了不少前置背景知识(主要集中于架构和分布式训练),最后整理出来了这一份,希望对大家有些帮助。
Introduction
Llama3基座模型原生支持了多语言、编程、推理和工具使用,最大的模型为405B,上下文128K,在训练过程中,主要优化了以下的地方:1. 提高了数据数量和质量;2. 用更多的token训练来scale up model;3. 用稠密的transformer架构,和SFT、RS、DPO进行后训练,有利于scaling up。
Overview
在这一段中,我们了解到Llama3的模型架构如下图:
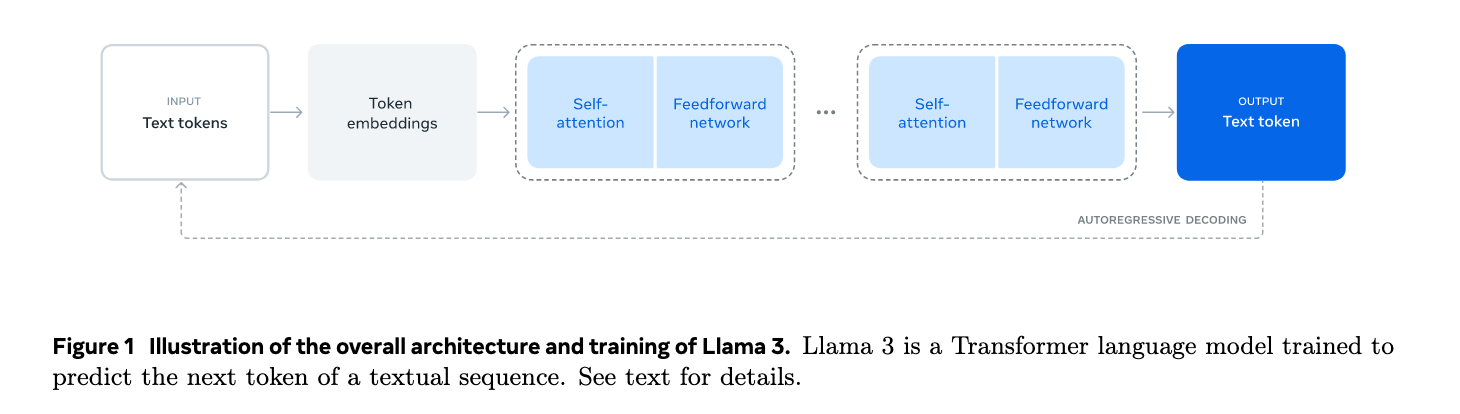
作者在这里给出了模型训练的两个阶段:
预训练: 用大规模的语料进行预训练,使模型具有理解语言的能力,分为两个阶段,第一段是8K token上下文,第二阶段是128K token上下文;
后训练: 通过多轮训练使得模型与人类反馈对齐,主要涉及SFT和DPO,在后训练阶段还让模型获得了工具使用的功能,最后还进行了安全方面的微调。
作者团队还在LLM的基础上添加模态,使得Llama可以支持多模态能力,作者给出了多模态训练的三个阶段:
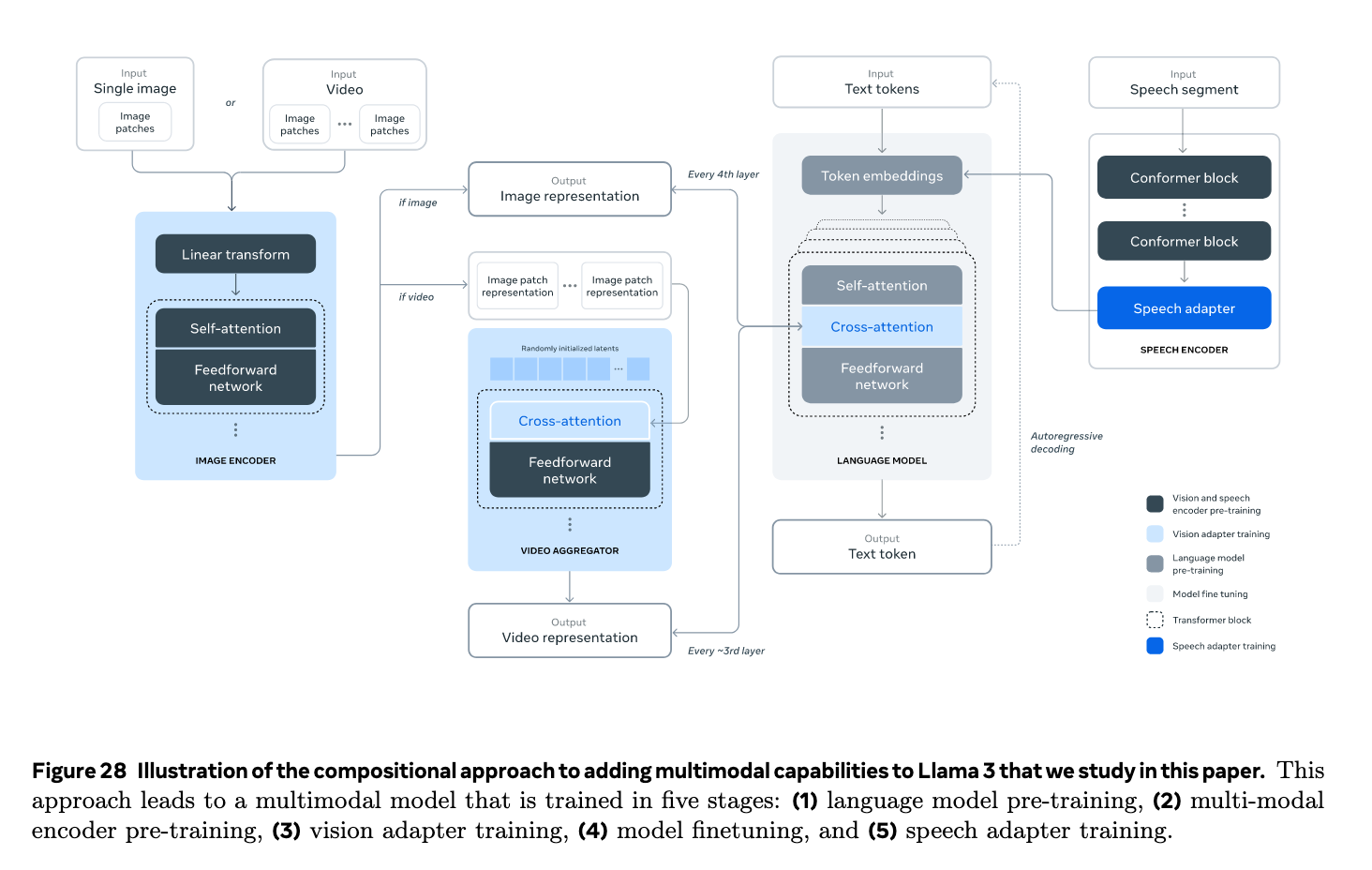
多模态编码器预训练: 添加模态首先肯定要训练一个编码器,针对图像,团队利用大量的图像-文本对训练encoder,让模型学会自然语言和图像之间的关系;针对语音,团队将语音输入的一部分mask起来,让模型自监督,尝试通过离散的token来重建这个mask的部分,让模型学会语音信号的结构;
视觉适配器训练: 接下来就是训练适配器,让的图像token的与文本的token对齐。Adapter中有一系列的cross-attention层,根据图像-文本对训练,在训练过程中也同时更新上面encoder的参数,但是维持基础语言模型的参数不变。同时还训练了一个视频适配器。
语音适配器训练: 与视觉adapter类似,同样是在微调阶段联合更新adapter和encoder的参数,不改变语言模型。同时作者还集成了一个文本转语音的系统。
Pre-training
现在进入模型训练的第一个阶段,Pre-training。
数据搜集
数据预处理:
模型的数据主要来自网页,所以首先对数据进行了安全过滤->HTML文本提取->去重提质(n-gram, minhash, KL散度);
针对代码和数学推理网页,先根据用Llama2标注训练的distilroberta分类,然后分别采取特定的过滤处理;
针对多语言数据,大体与之前相同,区别就是加了个语言分类模型,针对每个语种再去做数据处理,并且在训练的过程中要平衡多语言和英语语料token的比例。
数据组合:
训练数据组合的比例对模型质量也很重要,所以首先根据分类器,减少一些多余类别的数据数量,然后用不同比例训练小模型评估,最终获得合适的组合。
最终的组合:50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
数据退火:
针对相对数量比较少的高质量代码和数学公式语料数据,用退火能大大提升性能(主要是对于小模型,对大模型提升有限)。
作者还介绍了如何用退火评估数据质量:用30%权重待评估数据和70%权重原始数据的混合来训练一个已经训练了50%的模型,将学习率线性降低到0,根据模型的性能来评估数据集性能,这样比scaling law更快。
模型架构
作者指出,Llama3的架构和Llama2的区别不大,主要的性能提升来自于数据质量、多样性和scaling up。
问题1:在 3.2 节中:“We use grouped query attention (GQA) with 8 key-value heads to improve inference speed and to reduce the size of key-value caches during decoding.” GQA 和通常的多头注意力有什么区别?“reduce the size of key-value caches” 的主要意义是什么?
参考资料:《Llama 2: Open Foundation and Fine-Tuned Chat Models》
关于KV Cache:
LLM本质上是一种自回归的模型,也就是根据前面的输出预测下一个输出,对于causal attention,在训练的时候经过掩码是看不到后面的序列的,同样在LLM预测输出的时候,也不知道后面的序列,是用所有前面已知的序列做attention计算。
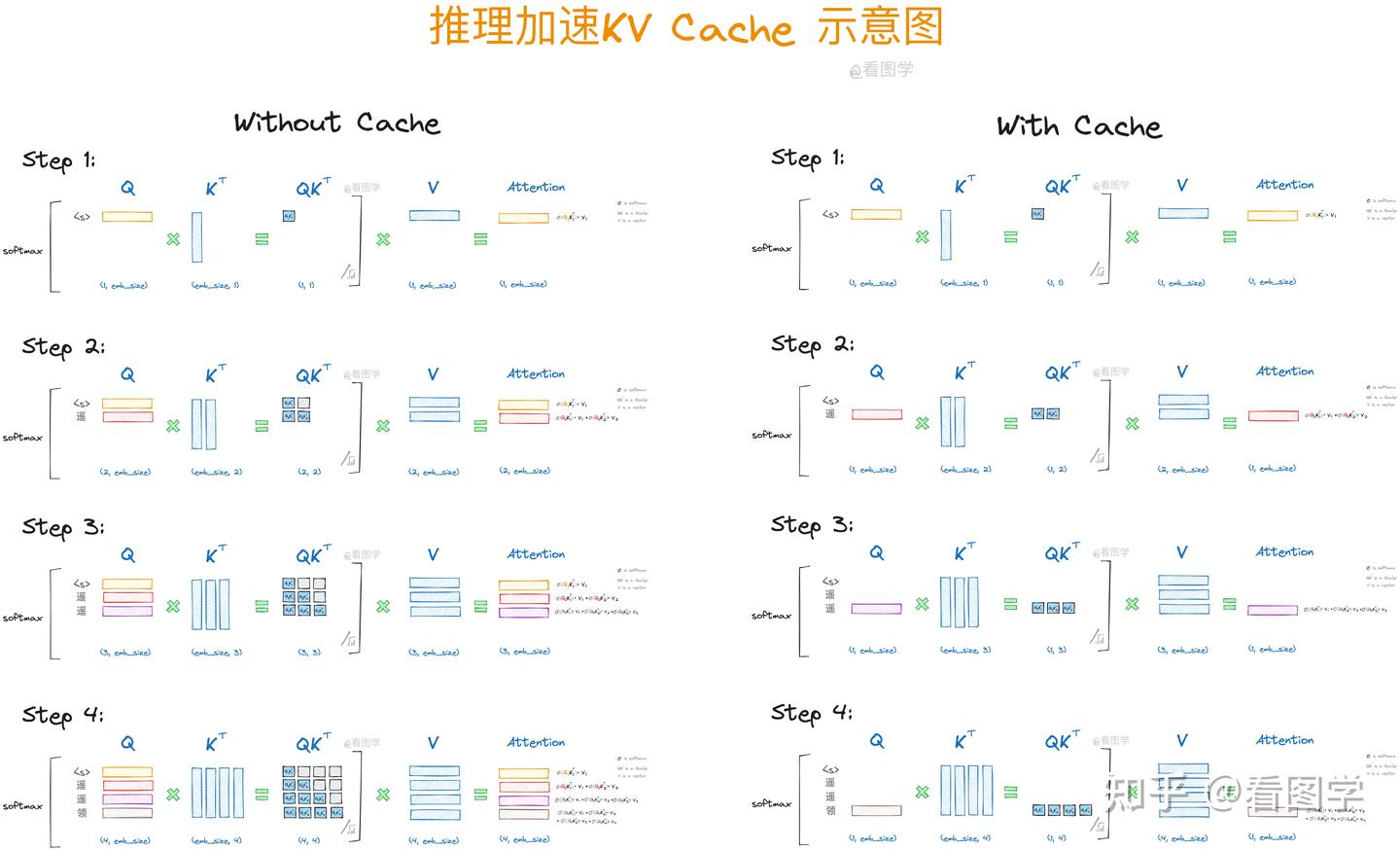
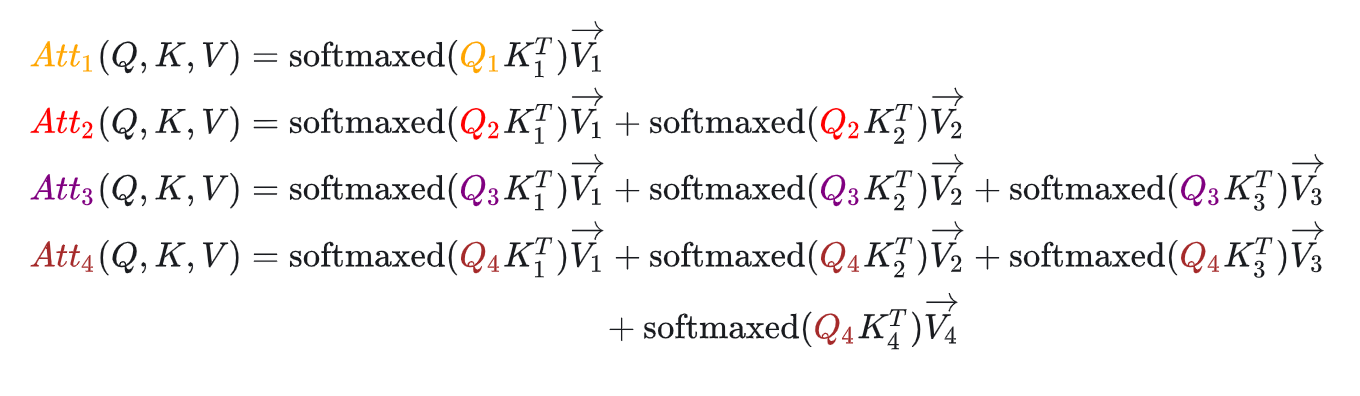
通过上面左侧的图可以看到,当我们逐token推理的时候,最新的只与每次的和截止到这一个token之前的K和V有关。这说明第一,我们不需要每次重新计算整体的attention,实际在推理的时候只是关心最后一个attention,再映射到词表,所以只要计算最后一个attention就可以;第二,我们不需要每次重新计算一遍之前token的K和V,只需计算新的K和V,与以前缓存的K和V合并,再与新的query做计算就可以。
这里缓存的K和V就是KV Cache,用来降低训练和推理所需要的计算量,加速训练推理过程。
关于GQA:
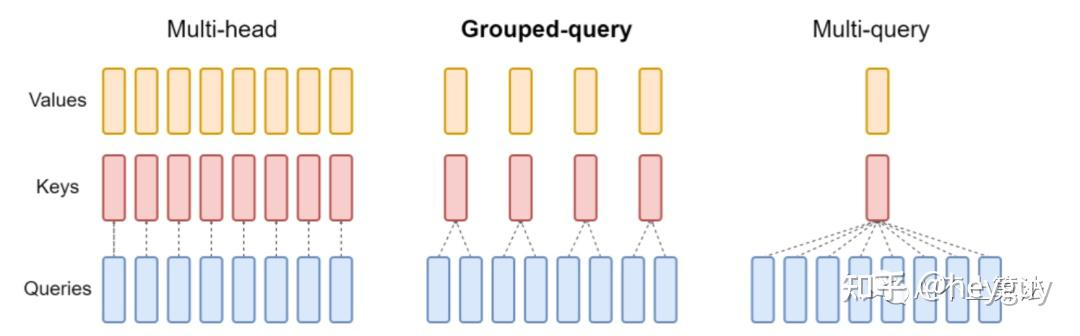
KV cache就是用空间换时间,但是GPU的显存有限,模型变大了KV cache也很大,这时候就可以通过GQA共享KV对节省显存空间。
GQA就是把多头注意力的头分成x组,每组里面共享相同的KV对,如果x=1,就是MQA,如果x=头数,就是MHA,这么做虽然会损失一些多头学到的不同表达,但是大大降低了显存使用。
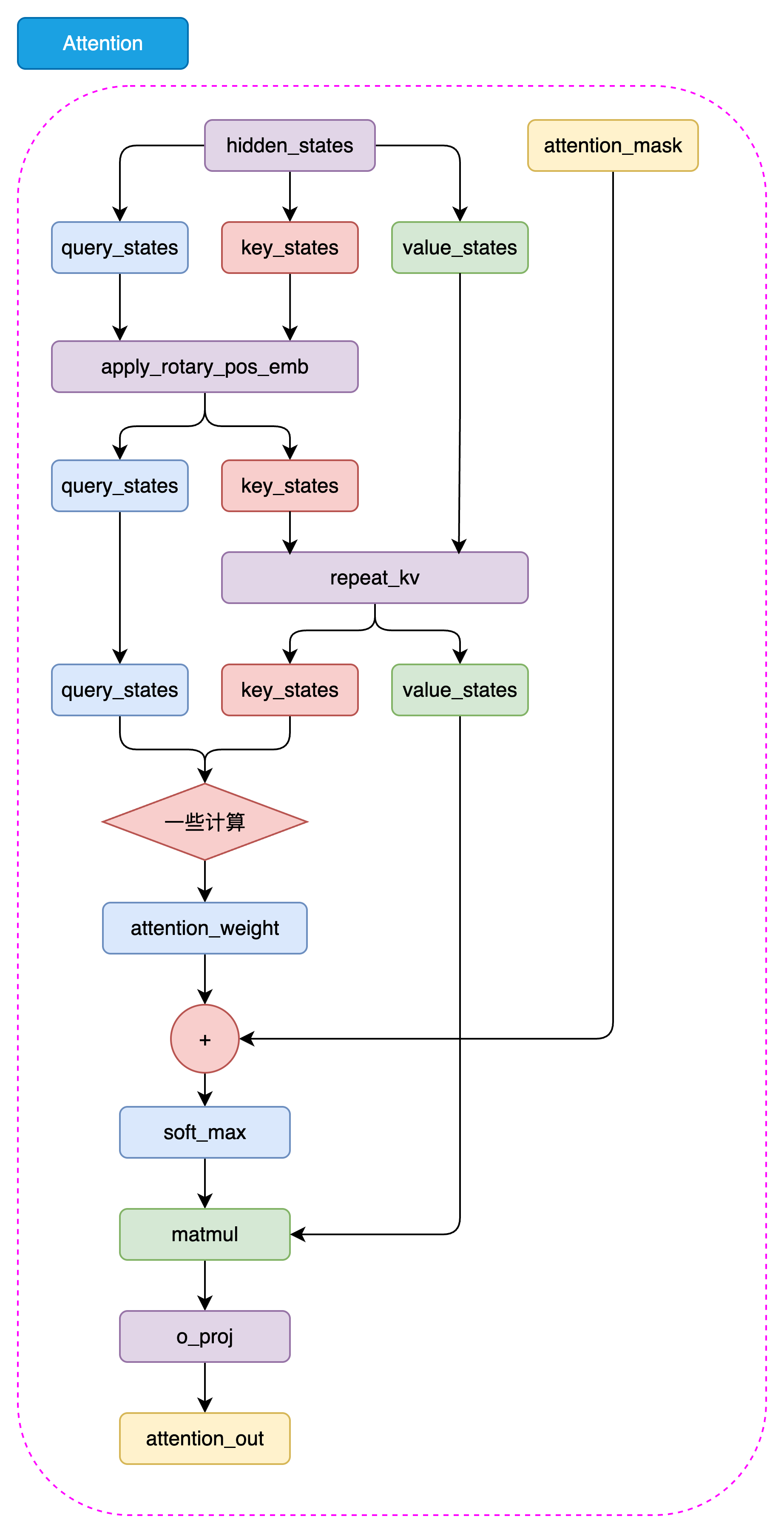
GQA的代码实现流程如下图:
Llama2 Architecture回顾
由于这里没有给出Llama2的模型架构,所以我们来回顾一下:
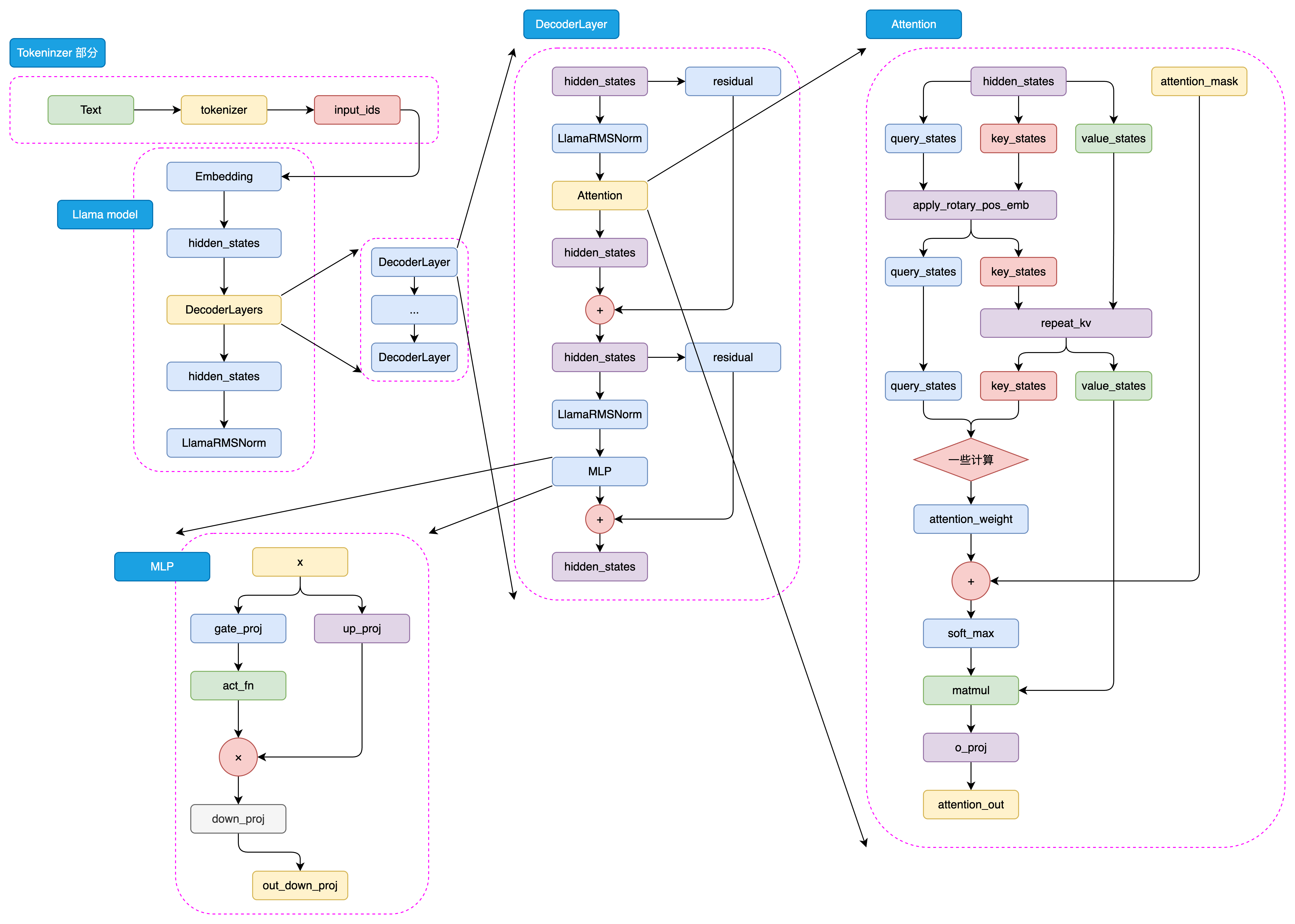
Llama3在Llama2上做的一些修改如下:
- 用了8 key value的GQA来加速推理速度,减少KV Cache
- 使用Attention Mask防止同序列中不同文档之间的注意力,优化了超长序列的持续预训练
- 训练了新的tokenizer,对英语的压缩率更高,并且新增了非英语的token
- 将RoPE的frequency超参数提升到了500000,支持更多的上下文
为什么调整frequency可以支持更长上下文?
参考资料:https://zhuanlan.zhihu.com/p/642884818
关于RoPE(旋转位置编码):
为了利用 token 之间的相对位置信息,假定 query 向量 和 key 向量 之间的内积操作可以被一个函数 表示,该函数 的输入是词嵌入向量 , 和它们之间的相对位置 :
接下来的目标是找到一个等价的位置编码方式,使得上述关系成立。
假定词嵌入向量的维度为二维(),这样就可以利用二维平面上向量的几何性质。RoPE提出了满足上述关系的一组函数 和 的形式如下:
用复数旋转角就可以表示两个向量之间的位置关系。
对于通用情况维度 ,则将词嵌入向量元素按“两两一组”分组,每组应用相同的旋转操作,且每组的旋转角度计算方式如下:
其中: 表示第 组(共 组); 10000是该组对应的旋转基频;每组内两个元素共享同一个 ,分别进行 和 旋转。
所以,简单来说,RoPE 的 self-attention 操作流程如下:对 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量;对每个 token 位置 ,计算对应的旋转位置编码(即对每个维度施加旋转矩阵);对每个 token 的 query 和 key 向量,按“两两一组”应用旋转变换;最后计算旋转后的 query 与 key 之间的内积,得到 self-attention 的结果。
所以提高基频的话,就像相当于减小了,也就支持更长的位置编码,更多的上下文。
Llama3的参数如下:
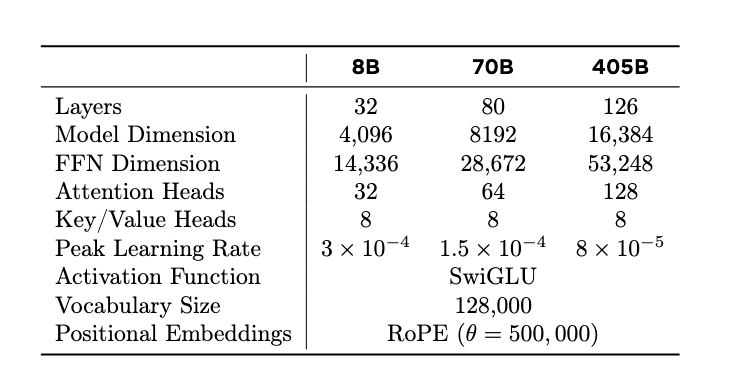
问题2:基于 3.2.1 节,用自己的话讲述 Llama 3 是如何确定其旗舰模型尺寸的。
用Scaling laws确定模型大小
正如我们在前面看到的,训练大模型很耗资源,所以需要通过训练小参数的模型来确定训练大模型的合适大小、参数等。
作者提出了这里的主要challenge,因为目前的Scaling law只是预测next-token prediction loss(也就是后文的NLL),但是没有预测实际benchmark表现的;同时小规模的pretrain模型的效果可能比较难推广到大模型上。
为了解决这些问题,我们就要“两步走”:
- 首先是拟合最佳模型NLL和训练所需算力(这里是FLOPs)之间的关系;
- 然后拟合NLL和实际benchmark accuracy之间的关系,在这里,为了解决向上推广的问题,作者特别强调加入了训练了更高FLOPs的模型和以前的Llama2模型,让整个拟合更加准确。
Experiment:
- 确定最佳模型,FLOPs和Training Token间的关系
首先就是训练一系列小模型,这里的参数是训练budget FLOPs 到 FLOPs之间,参数40M到16B。
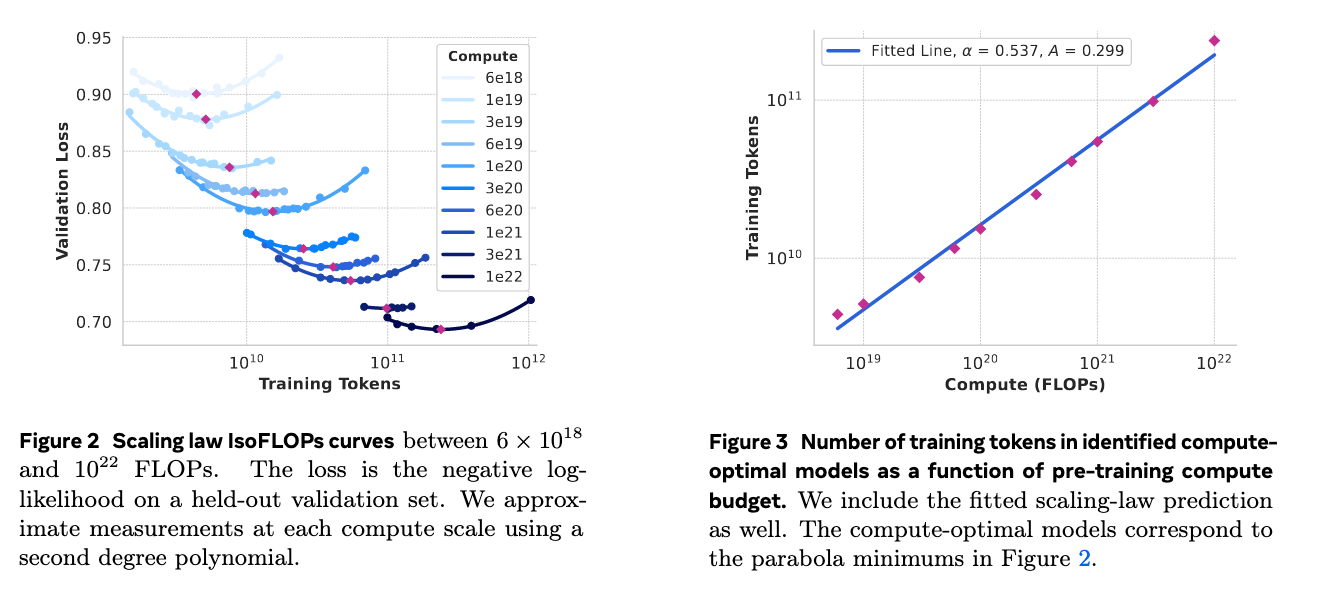
利用 Scaling Laws 预测模型 Loss 与计算规模的关系
根据上面Figure2,我们获得了loss(在一个另外的验证集上测试的,避免过拟合)和训练budget以及训练用的总token之间的关系。作者根据趋势用二次多项式拟合了每个budget下的loss-token曲线,取最低点为不同budget的compute-optimal模型,也就是这个budget下loss最小的模型;接着把这些compute-optimal模型的FLOPs budget 与训练token 按照下面的幂次形式做了个拟合:
结果如figure3,求出训练一个402B参数的模型,花费 FLOPs,需要16.55T个token(与最终取的15.6T差不多),作者又观察到随着budget增加,losFLOPs曲线更平缓,token数对模型性能的影像不大,所以最终选择了405B为尺寸。
- 确定FLOPs和downstream benchmark间的关系
作者选择(1)里面训练FLOPs比较大的compute-optimal模型,将归一化的NLL与训练FLOPs线性拟合,然后根据趋势用sigmoidal relation(毕竟Accuracy的范围就是[0,1])拟合NLL和benchmark accuracy之间的关系,还加入了Llama2的模型,这样一来,将根据405B模型推算的FLOPs代入求出NLL,在将NLL代入就可以得到预测Accuracy,经过验证还是挺准的。
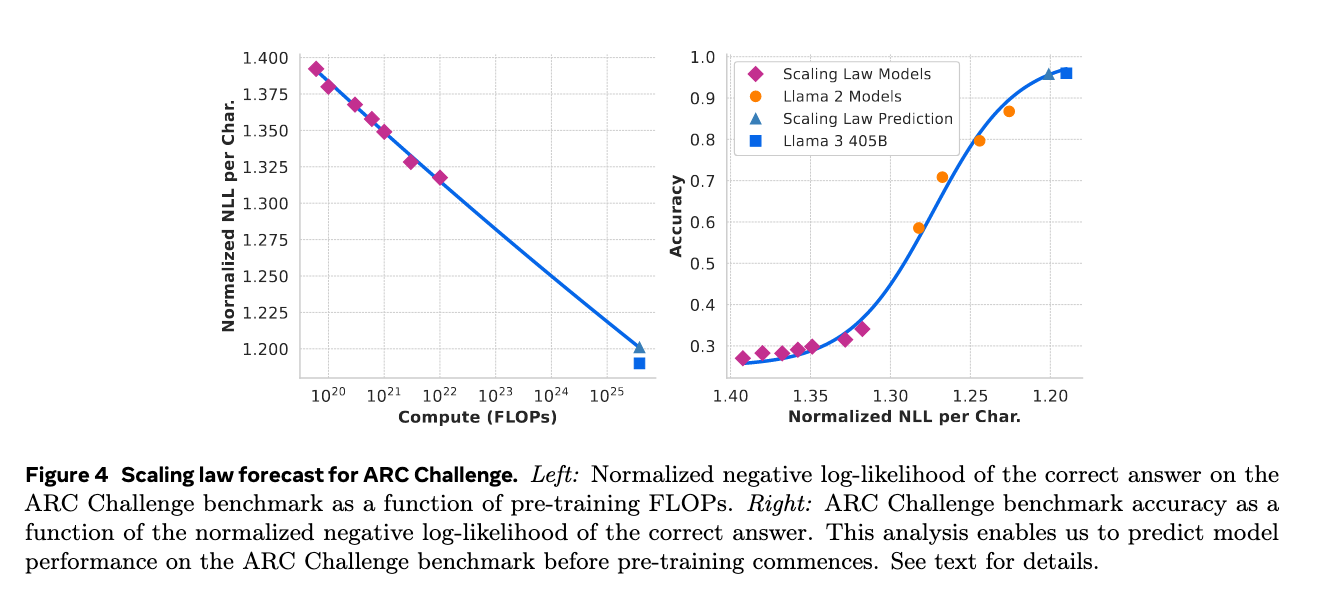
NLL 预测值与下游任务基准测试准确率(Benchmark Accuracy)的拟合关系
问题2结束
Infrastructure, Scaling, and Efficiency
Infrastructure
这一段的内容主要是介绍了训练模型用的硬件和网络设施,不得不感叹Meta果然财大气粗。
Parallelism
Llama3使用了一个4D parallelism的机制,结合了Tensor Parallelism、Pipeline Parallelism、Context Parallelism和Fully sharded data parallelism (which shards the model, optimizer, and gradients)。
问题3:简要概括 3.3.2 节中提到的四种 parallelism 的主要特点。
为了回答这个问题我去仔细研究了一下之前了解不多的parallelism的问题,为了比较全面所以写多了点:)
Fully sharded data parallelism:
参考的文档:
https://zhuanlan.zhihu.com/p/650002268;
https://github.com/chunhuizhang/pytorch_distribute_tutorials;
《PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel》;
在展开我对于FSDP的理解之前,我觉得应该先明确一些通信原语的定义:
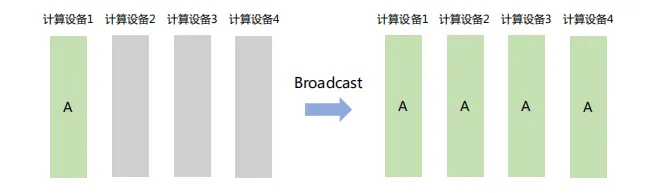
(1) Broadcast
将数据从主节点发送到集群中的其他节点。如下图,计算设备1将大小为1xN的张量广播到其它设备,最终每张卡输出均为1×N矩阵:
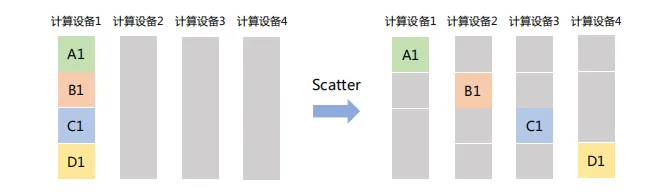
(2) Scatter
主节点将一个大的数据块分割成若干小部分,再将每部分分发到集群中的其他节点。如下图,计算设备1将大小为1xN的张量分成4个子张量,再分别发送给其它设备:
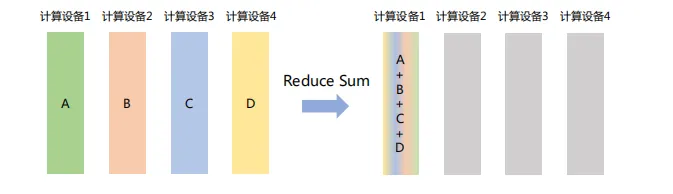
(3) Reduce
将不同节点上的计算结果进行聚合。Reduce操作可以细分为多种类型,包括SUM(求和)、MIN(求最小值)、MAX(求最大值)、PROD(乘积)、LOR(逻辑或)等,每种类型对应一种特定的聚合方式。如下图所示,Reduce Sum操作将所有计算设备上的数据进行求和,然后将结果返回到计算设备1:
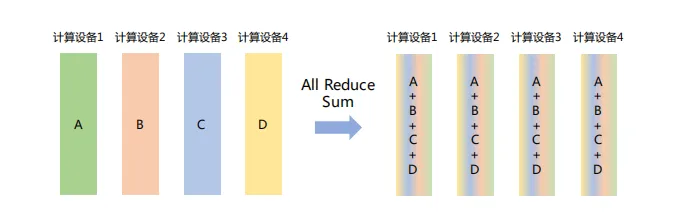
(4) All Reduce
在所有节点上执行同样的Reduce操作,如求和、求最小值、求最大值等。可通过单节点上Reduce+Broadcast操作完成。
如下图所示,All Reduce Sum操作将所有节点上的数据求和,然后将求和结果Broadcast到所有节点:
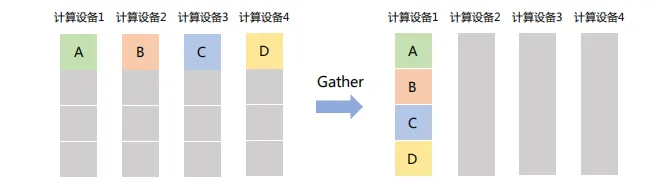
(5) Gather
将所有节点的数据收集到单个节点,可以看作是Scatter操作的逆操作。
如下图所示,Gather操作将所有设备的数据收集到计算设备1中:
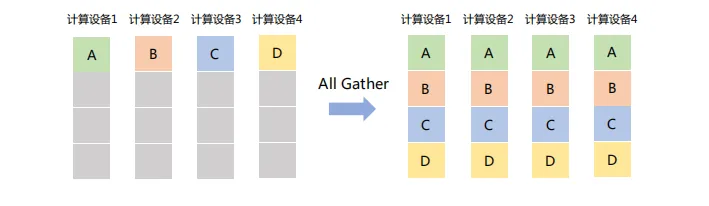
(6) All Gather
在所有节点上收集所有其他节点的数据,最终使每个节点都拥有一份完整的数据集合。可以视为Gather操作与Broadcast操作的结合体。如下图所示,All Gather操作将所有计算设备上的数据收集到各个计算设备。
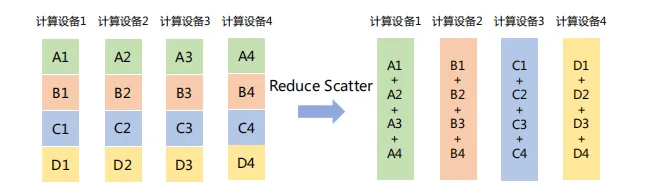
(7) Reduce Scatter
将每个节点的张量分割成多个块,每个块分发给不同的节点,再在每个节点执行Reduce操作(如求和、平均等)。如下图所示,Reduce Scatter操作将每个计算设备中的张量分割成4块,并发送给4个不同的计算设备,每个计算设备对接收到的块执行Reduce Sum操作。
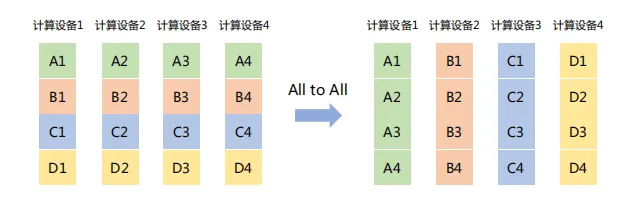
(8) All to All
将每个节点上的数据分割成多个块,并将这些块分别发送给不同的节点。
如下图所示,All to All操作将每个计算设备中的张量分割成4块,并发送给4个不同的计算设备。
FSDP是在DP和DDP基础上演化出来的。Data Parallelism发明出来是为了解决训练数据太大, 内存不够、batch size开不大的问题,所以最朴素的DP就是把一个大的batch分割成小batch给不同的GPU,模型参数在每个GPU上复制一遍,然后在每个GPU上针对每个小batch做前向传播。
下一步如果是DP的话,就把每个GPU的output送到一个主GPU上计算损失梯度,然后把损失梯度反传回原来的所有GPU做反向传播计算梯度,再把梯度汇聚到主GPU更新参数并广播给其他GPU;如果是DDP(Distributed Data Parallelism)就在每个GPU上前向反向传播计算出梯度,然后通过All-Reduce将所有GPU上的梯度汇总平均,然后根据汇总平均的梯度更新自己的参数(所有更新后的参数都保持一样)。显然DDP的效率比DP更高,不会受到单卡瓶颈。
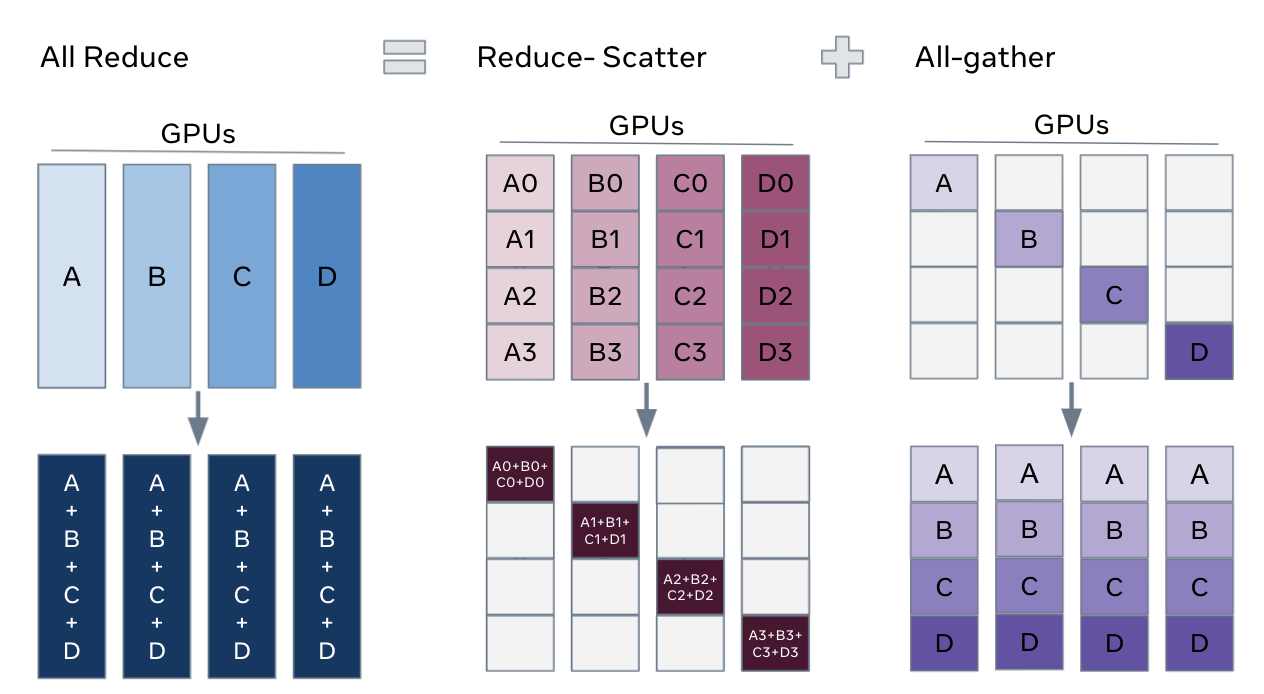
接下来就是FSDP,虽然用了DDP可以开大batch size,但是GPU上除了数据之外,模型参数、优化器参数和梯度也是占用内存的大头,而DDP需要每个GPU都存一份完整模型的copy,所以FSDP就是参考了ZeRO分片的原理,对优化器状态、梯度和模型权重参数进行了分片:

FSDP的核心就是把DDP之中的All-Reduce操作分解为独立的 Reduce-Scatter和All-Gather 操作,这样一来就可以把模型参数也分配到不同的GPU上,Gather运算完了就释放,节省了不少GPU内存。
我从PyTorch FSDP论文中截取的FSDP流程图如下,简单的来说,就是先把模型分成不同的FSDP Unit(这里一个Unit里面有两层):
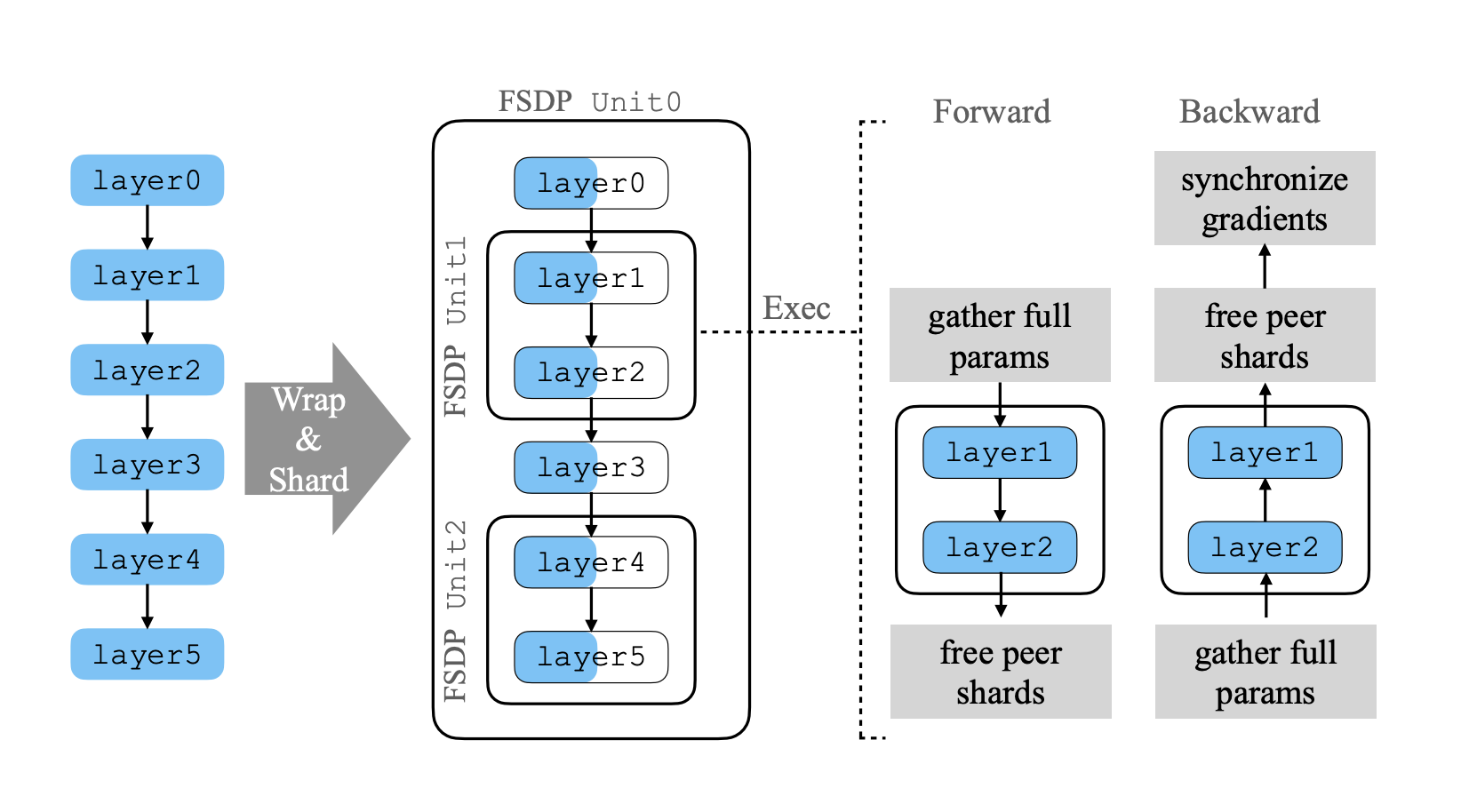
对每个Unit我们执行FSDP,把这个Unit里面的参数分配到不同的GPU上,也就是Sharding;之后我们在一个GPU上针对不同的数据块做前向传播,就要先从别的GPU把模型参数Gather过来,然后在计算完后释放,把内存留给其他计算。
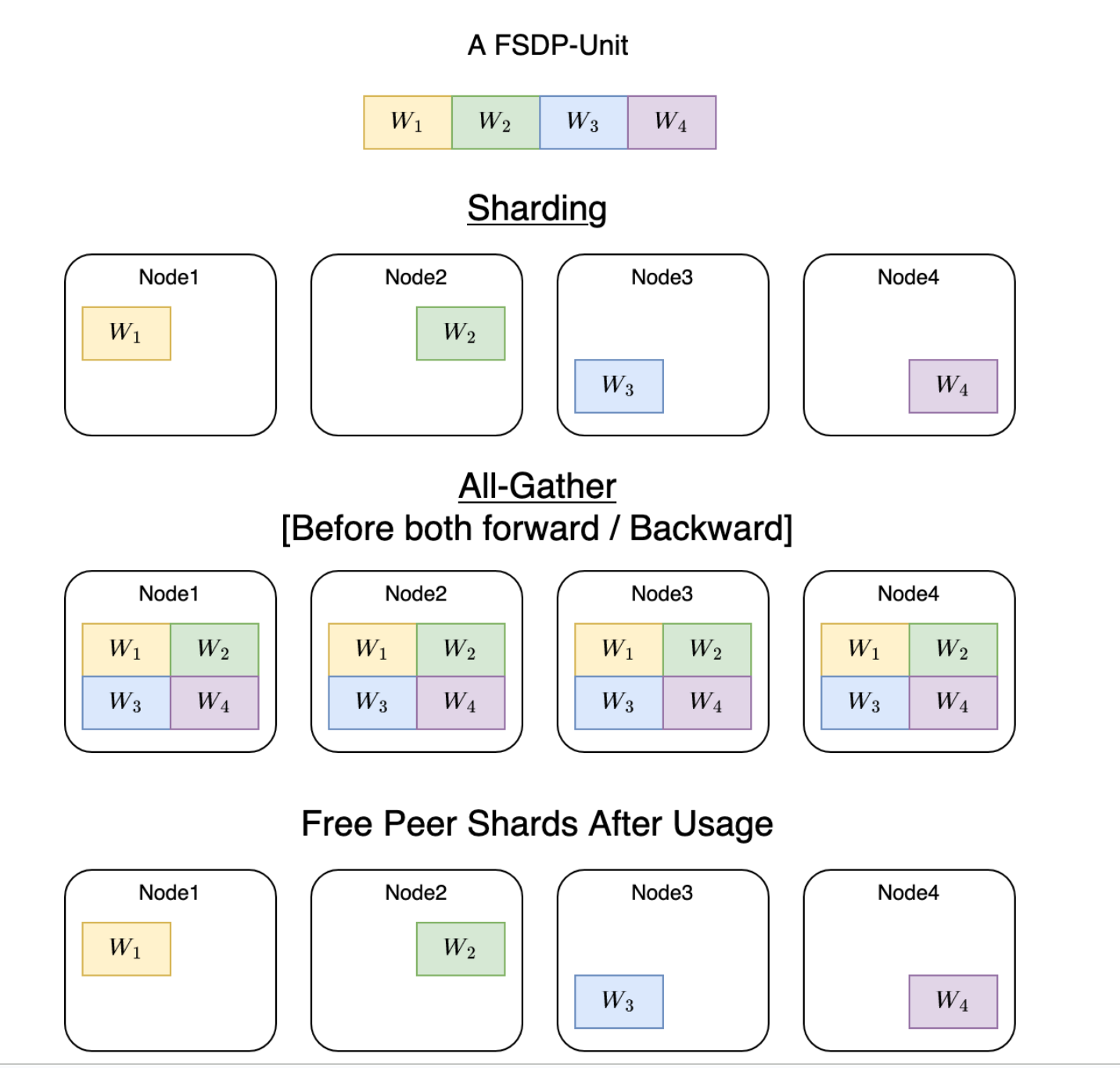
同理,在反向传播的时候也需要先Gather,计算出针对不同数据块的Gradient,然后做Reduce Scatter,也就是从其他GPU上拿到并汇总属于自己这个模型参数对应部分的Gradient,最后释放不需要的Gradient和模型参数,用自己的Gradient,结合对应自己这部分参数的优化器分片,更新自己的权重参数,也就实现了优化器状态、梯度和模型权重参数的分片存储并行运算。
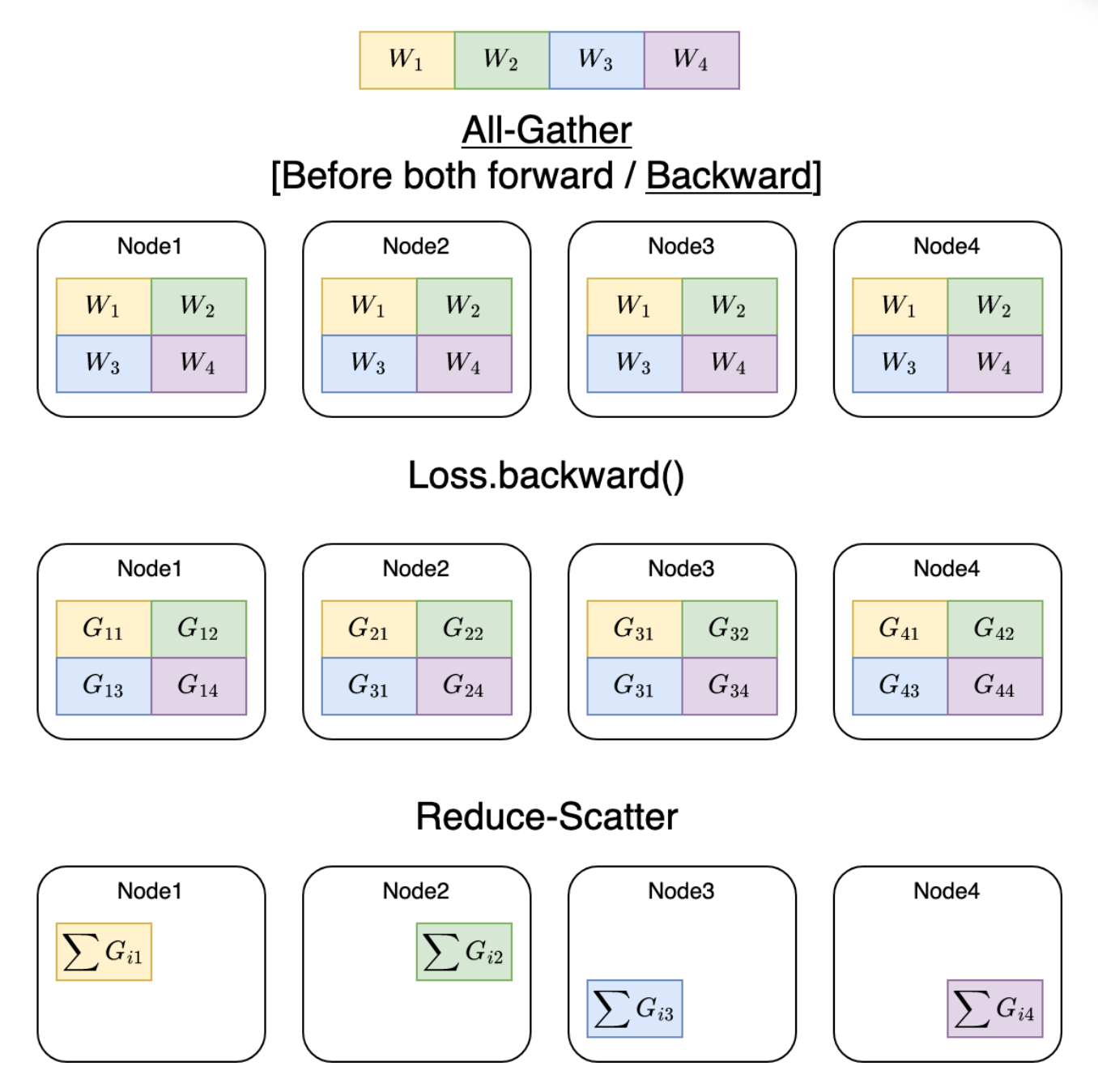
汇总起来以上内容的完整流程图如下:
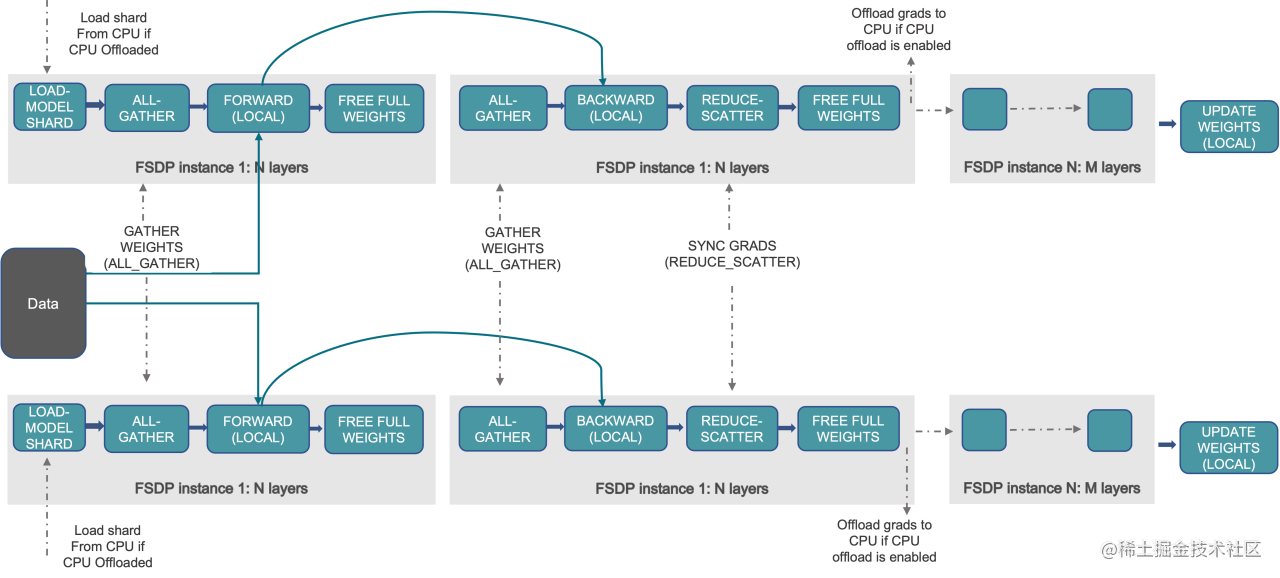
论文中,如果考虑不同Unit,完整的FSDP流程如下,还涉及All Gather和前向传播的并行,以及不同Unit根据自己所含layer的顺序的交替前向传播(Unit0,1),这里就不多赘述了。
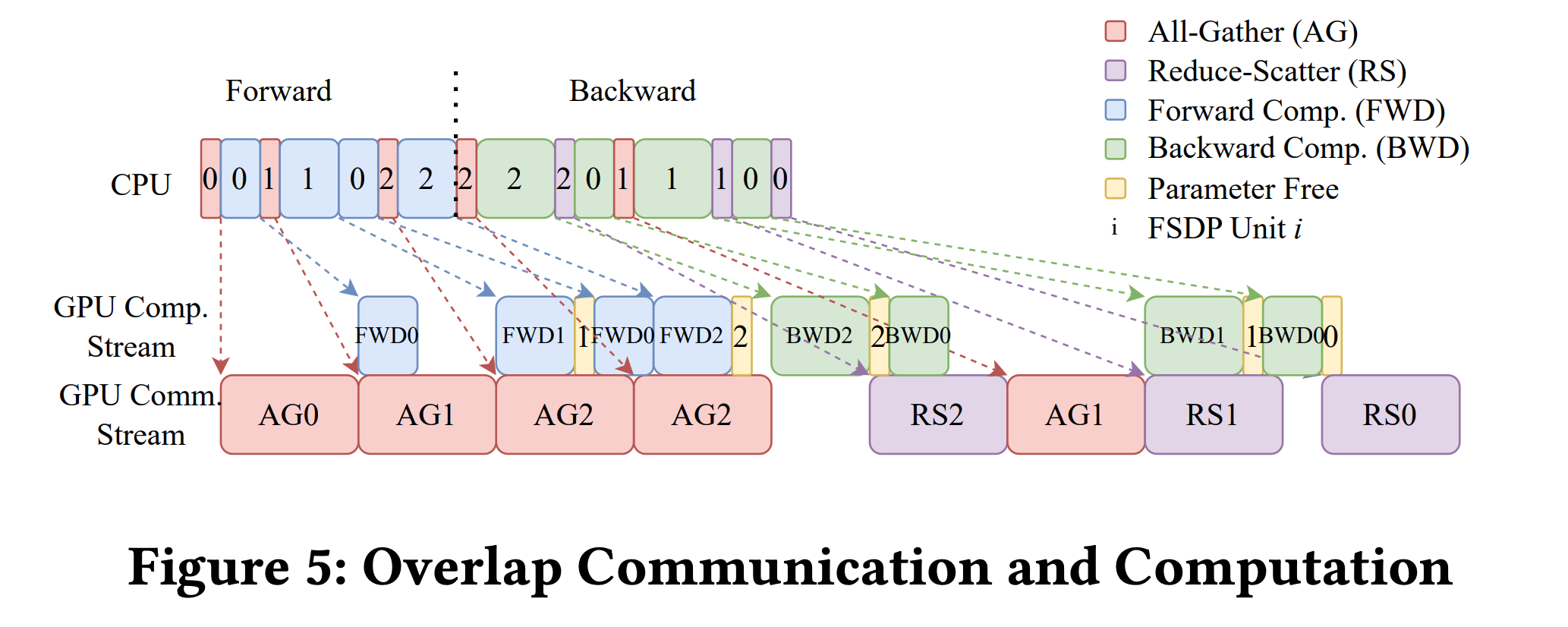
总的来说,FSDP的特点就是在数据并行的基础上,对优化器状态、梯度和模型权重参数分片存储,需要的时候就汇总,计算后立刻释放,大大节省了GPU内存空间。
FSDP在Llama3中的一些不同点:
在Llama3中训练中的FSDP也是切分了优化器状态、梯度和模型权重,但是对于模型参数没有采取上面提到的计算后立刻释放的操作,而是在反向传播之后释放,这样用内存换取节省了一次all-gather的通信开销。
Tensor Parallelism:
参考的文档:
https://zhuanlan.zhihu.com/p/657921100;
Tensor并行的目的也是为了节省内存,把大的模型张量分割到不同GPU上并行计算,最后再拼接起来。Tensor并行的原理比较简单,就是利用了大的矩阵乘法可以被拆分为小矩阵乘法后拼接的形式,比如下面的行并行和列并行:
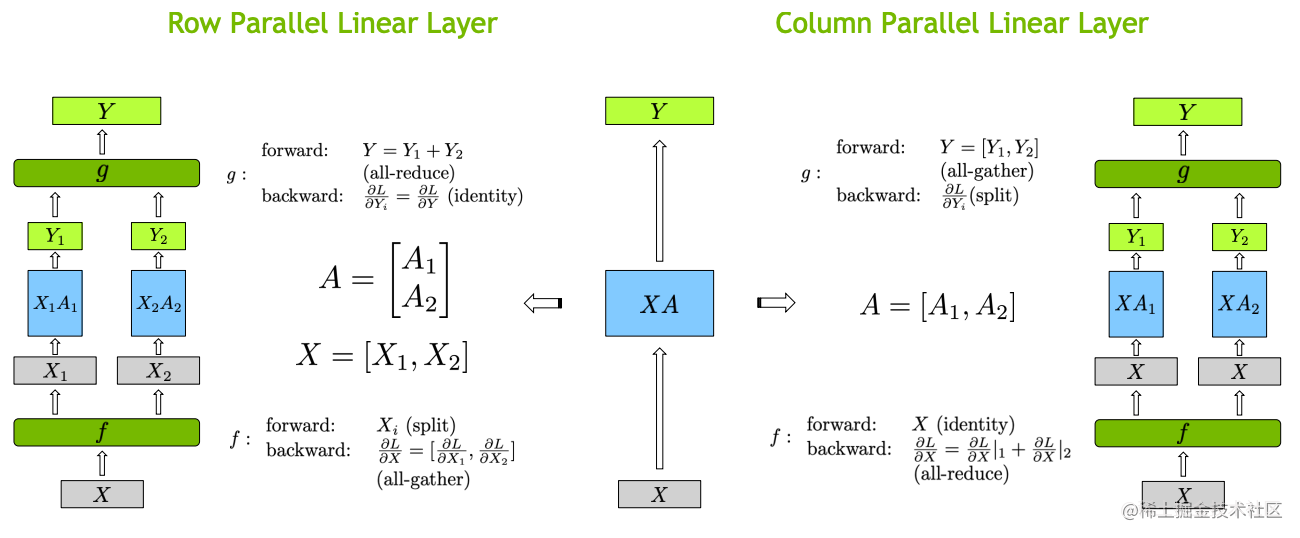
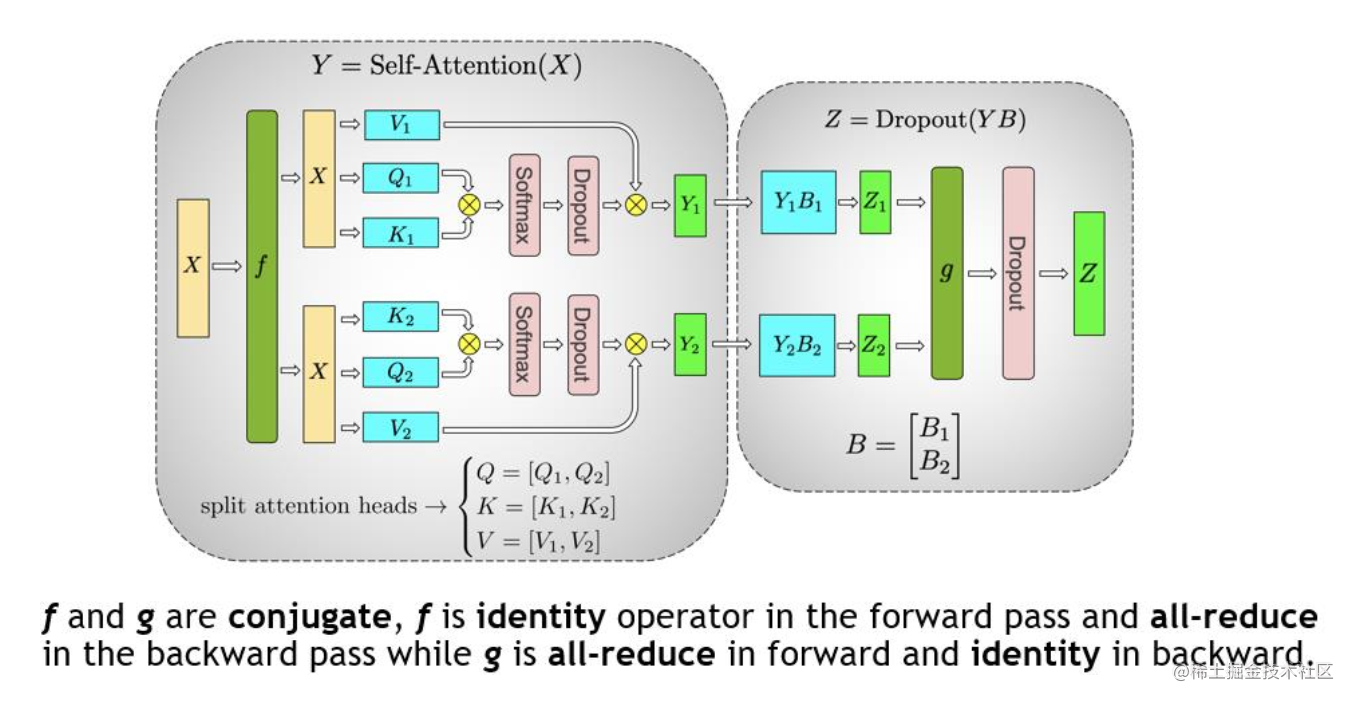
对于MLP很好切分,那么对于Attention也可以张量切分,也就是相当于Multihead Attention,对三个参数矩阵Q,K,V,按照列切割 ,每个头放到一块GPU上,做并行计算,对线性层按照行切割。
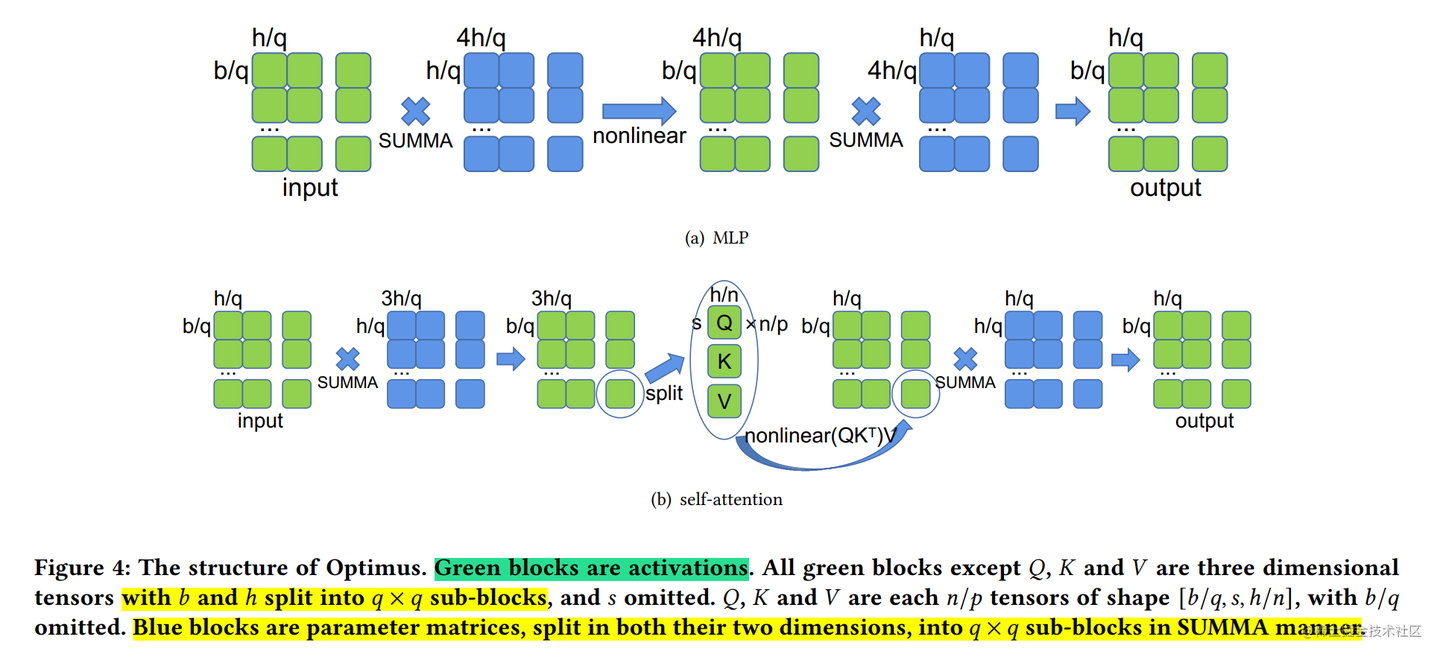
除了对weight做1D切分,还可以对input也做切分形成2D Tensor并行,再继续划分形成3D的Tensor并行,大体的原理和1D的是类似的,论文中也没有过多关于Tensor并行的修改细节。
Pipeline Parallelism:
参考的文档:
https://zhuanlan.zhihu.com/p/653860567;
《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》;
流水线并行就是把一个模型的不同层的训练拆分到不同的GPU上执行,在训练的时候按照层的顺序逐一进行,最简单的形式如下图,4个GPU按顺序对自己的Stage进行前向和反向传播,把每层的结果进行通信。
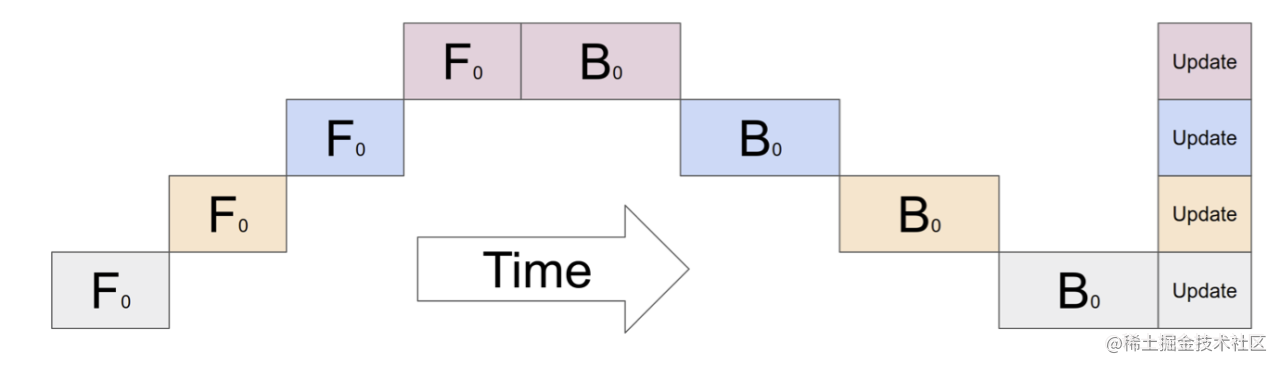
这么做的问题就在于每一时刻都只利用了一个GPU,全过程存在没被利用上的GPU bubble占比为 ,随着GPU数量增加,bubble的比例就会越高。
首先优化的方法就是利用data并行,将输入的数据的mini-batch进一步分割份成为micro-batch,然后先整体前向传播,再后向传播,由于batch变多了可以并行运行,所以总体的bubble占比为 也变小了:
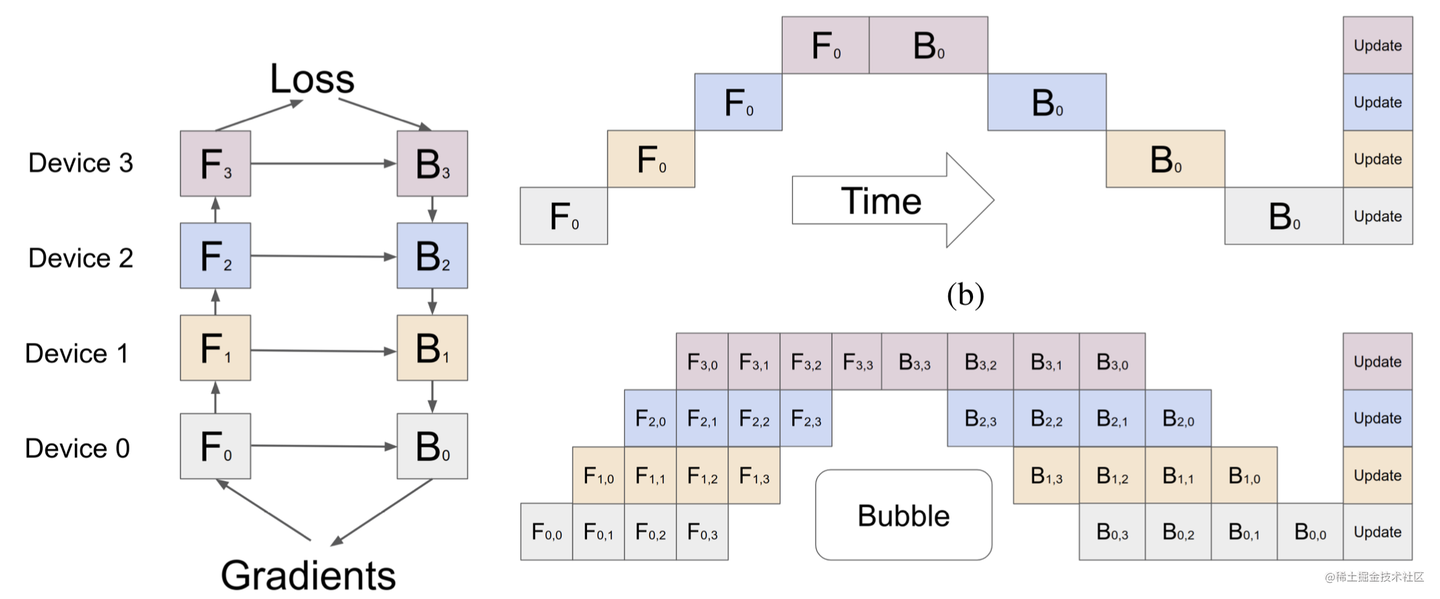
上面的方案是F then B,forward完缓存了很多的micro-batch中间变量和梯度,为了进一步提高显存利用率,我们可以采用1F1B,把每个micro-batch的前向和反向传播交叉进行,先完成反向传播的batch就可以把自己的内存空间释放出来给后面的过程。
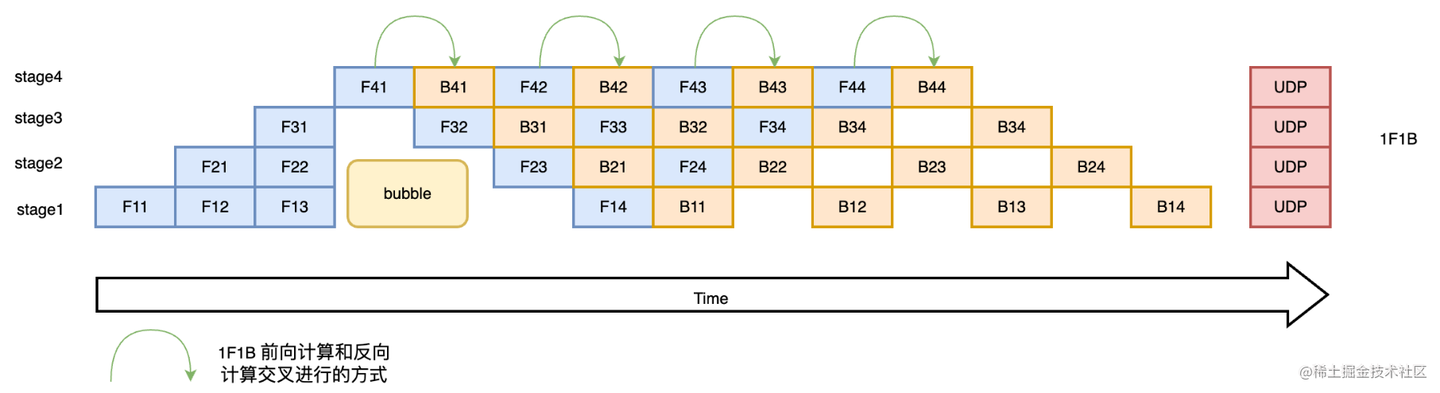
在1F1B基础上进一步,我们采用交错式1F1B还可以进一步降低bubble比例,这就接近了Llama3采用的流水线并行方式。
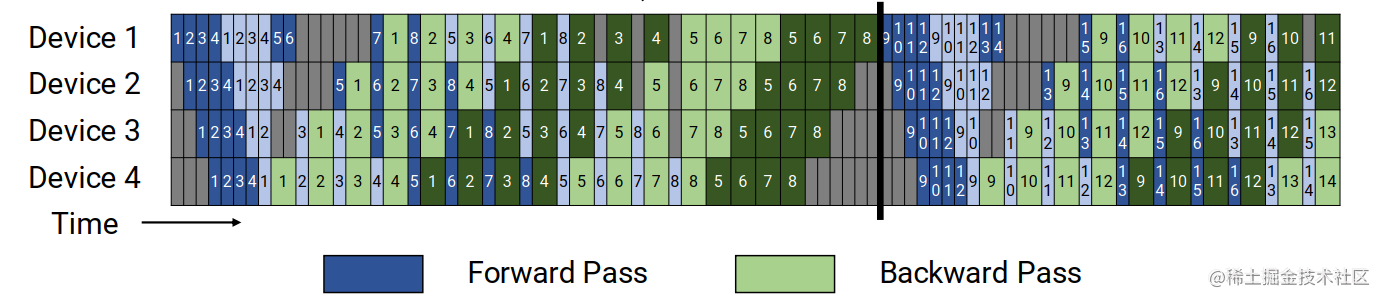
(深色代表1-8,浅色代表9-16 virtual stage)
核心思想是在设备数量不变的情况下,用通过构建虚拟流水线,通信量换取更少的bubble。把前面的4个stage继续分割成更小的virtual stage,比如原来一个device负责一个stage,每个stage被分为4个virtual stage,一共16个virtual stage。现在每个device一轮负责两2个virtual stage(这被称为1个model chunk),让前向传播轮两次,一次是1-8,结束了以后立马从头就可以进行9-16virtual stage的前向传播,同时开始1-8virtual stage的反向传播,这样就大大提升了GPU利用率。
这个方法的限制就是要求一个mini-batch中的micro-batch数量是流水线中的设备数量的整数倍,不然无法overlap。
Llama3中对Pipeline parallelism的优化:
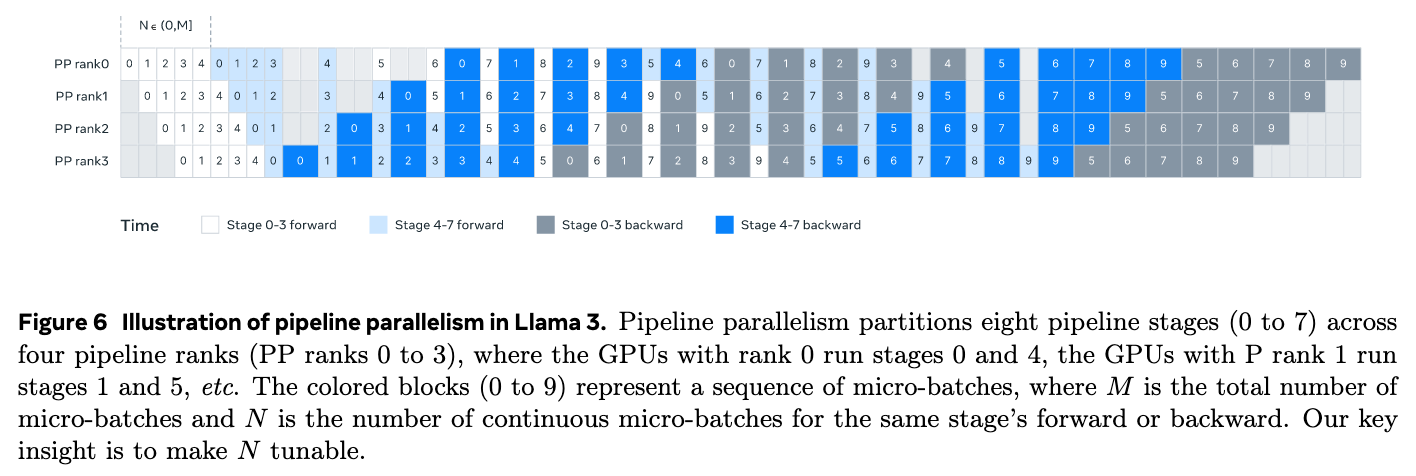
论文中提出的PP challenge有三点:
- 交错式1F1B对micro batch要求其数量为流水线并行数量整数倍,但是预训练可能需要灵活调整batch size:
Llama3做出的调整如上图是修改了交错1F1B的方式,比较看到他们把一些前向传播过程延后了一点,使得现在流水线数量是4,但是5个batch依然可以工作; - 第一个stage由于embedding和warming up会耗费更多内存:
- 在最后一层之后需要计算output和loss,造成了延迟瓶颈:
Llama3让stage1的第一个chunk只有嵌入层,而最后一个stage的最后一个chunk只有输出投影和损失计算,没有transformer层,平衡了负载和每个阶段的延时。
此外他们还用了异步点对点通信,移除每个stage不需要的input和output tensor等进一步优化。
Context Parallelism:
参考的文档:
https://zhuanlan.zhihu.com/p/683714620;
https://github.com/chunhuizhang/pytorch_distribute_tutorials;
《DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models》;
由于现在模型对长上下文的要求比较高,而且Attention的内存需求对序列长度又是的,所以需要通过切分输入context到不同GPU上,每个GPU只计算一部分context的Attention,优化内存使用。
一种比较常见的实现方式就是ring-attention,通过每次轮换不同GPU上的被拆分的KV对计算Attention,再使用修正和和聚合得到最终结果:
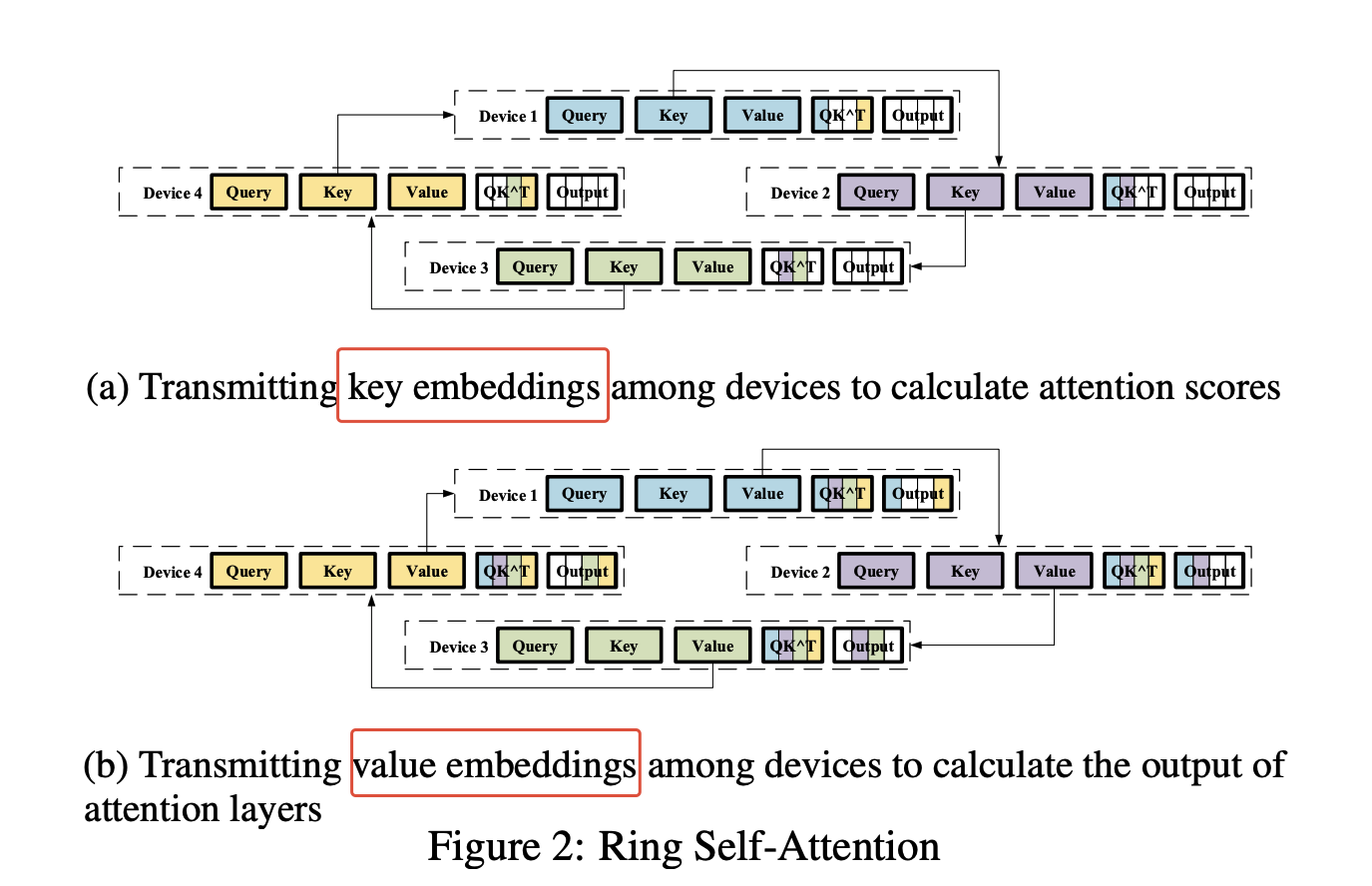
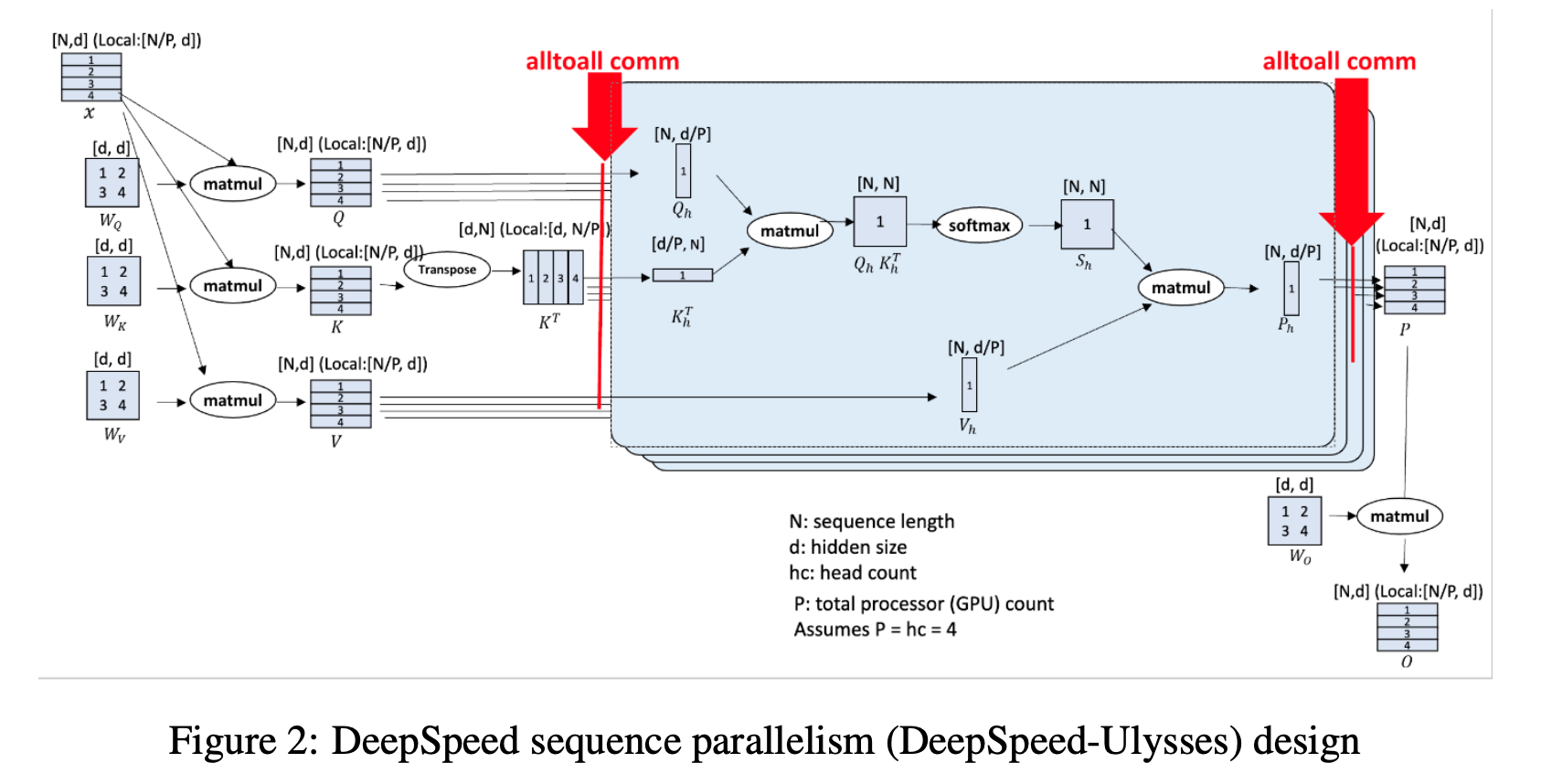
但是我觉得Llama3这里的Context并行更像Ulysses这里的方法,也就是在切分QKV和input context之后,在计算Attention的时候先all-gather形成完整的KV对,对保持不变的切分Q进行注意力运算,最终再合并起来。由于切分了Q,所以每个卡上运算的内存大大降低了。
Llama3中对Context parallelism的优化:
- 把输入序列分成了Context并行chunk的两倍,每个卡获得关于中心对称的两个context切片,这么做是为了平衡mask attention中Q的计算负载,如下图:
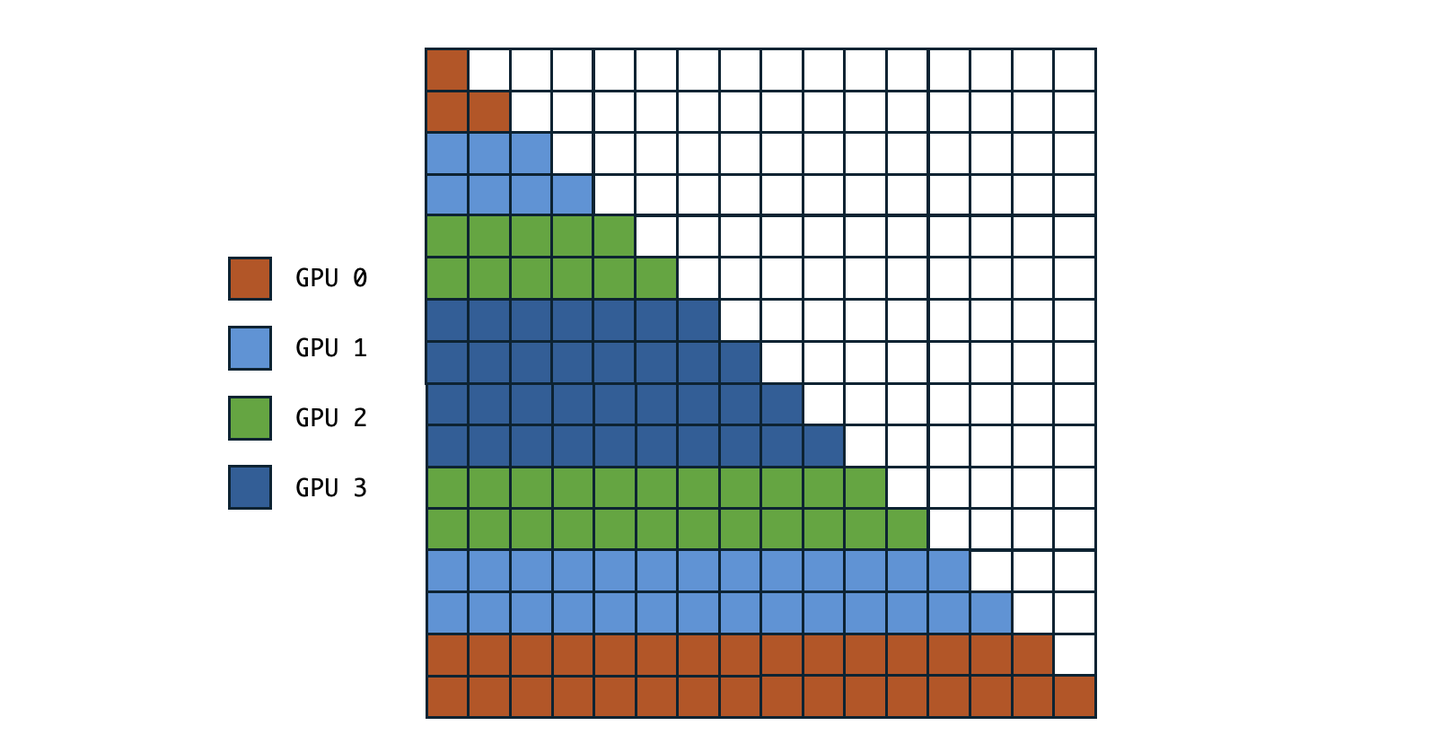
Llama 3 针对 Masked Attention 负载平衡的 Context 切片优化 - 类似上面Ulysses的思路,作者说用all-gather的合理性是这样可以支持更多的attention mask,以及由于用了GQA的KV很小,所以延迟可以接受。
通过context并行,Llama3也是成功把上下文从8K提升到了128K tokens。
Llama3的4D Parallelism:
![Llama 3 训练中各并行维度 [TP, CP, PP, DP] 的通信层级排列](/images/blog/llama3-tech-report/attachments/Pasted%20image%2020250922140814.png)
一番折腾终于完成了模型训练的并行。作者还按照不同并行化需要的通信需求排列了这些并行的顺序。最内层的并行处理延迟更低,外层延迟更高,Llama3对并行的排列顺序从内到外是:[TP, CP, PP, DP]。
问题3结束
Collective Communication
Reliability and Operational Challenges
一些炼丹崩溃的展示
Training Recipe
问题4:根据 3.4 节,Llama 3 的预训练分成几个阶段?你认为这种做法相比只设一个阶段有什么好处?
Llama 3预训练分为三个阶段:初始预训练、长上下文预训练、退火。
initial pre-training
首先是用AdamW优化器预训练,一些参数是:峰值学习率为 ,linear warmup 8,000 step,余弦学习率衰减,在1,200,000步内衰减至。
作者提到,他们在训练早期用了小batch来提高训练稳定性(加上warmup即使batch小也不会震荡太大,小batch有利于加速收敛),后期逐渐翻倍batch size和input length以提高训练效率,这么做的loss曲线比较平缓。
这个阶段的pre-training data是经过前面提到的预处理的,加入了更多非英文语料,还提高了数学推理的比例,详细见前面。
long context pre-training
在预训练的最后,他们才在128K token上做训练,因为如果在前面就上这么长的上下文的话,运算量的要求就很大,想让模型收敛花的时间和算力就更多。他们逐渐增长序列长度直到模型适应,再继续增长(“模型适应”表明 a.模型在短上下文评估中的性能已完全恢复,并且 b.模型完美解决了该长度的“大海捞针”任务。(前面results中有提))。
退火
参考资料:https://zhuanlan.zhihu.com/p/693076242
在训练最后40M个token的时候,他们线性衰减学习率至0,保持上下文长度为128K个token。参考一些资料,可能是当我们在模型训练的最后阶段的时候loss下降应该不快了,这个时候降低lr可以让模型更快找到一个sharp minimum,让loss更低,同时llama中又在这个阶段把数据换成了高质量数据,高质量数据的gradient比起低质量数据可能更准确,也就更利于我们找到saddle point。最终用polyak(平均)集成多个退火中的模型weight,产出最终模型。
多个阶段有什么好处?
- initial pre-training先用比较小的batch和比较小的sequence length,收敛速度会更快,而且迭代时间会更短;
- long context pre-training再逐渐加入长序列,可以进一步优化模型的长上下文性能;
- 在最后退火,让loss尽快缩小收敛;
这么做比起一个阶段,耗时更短效率更高,并且loss也可以控制的比较平缓;
问题4结束
Post-Training
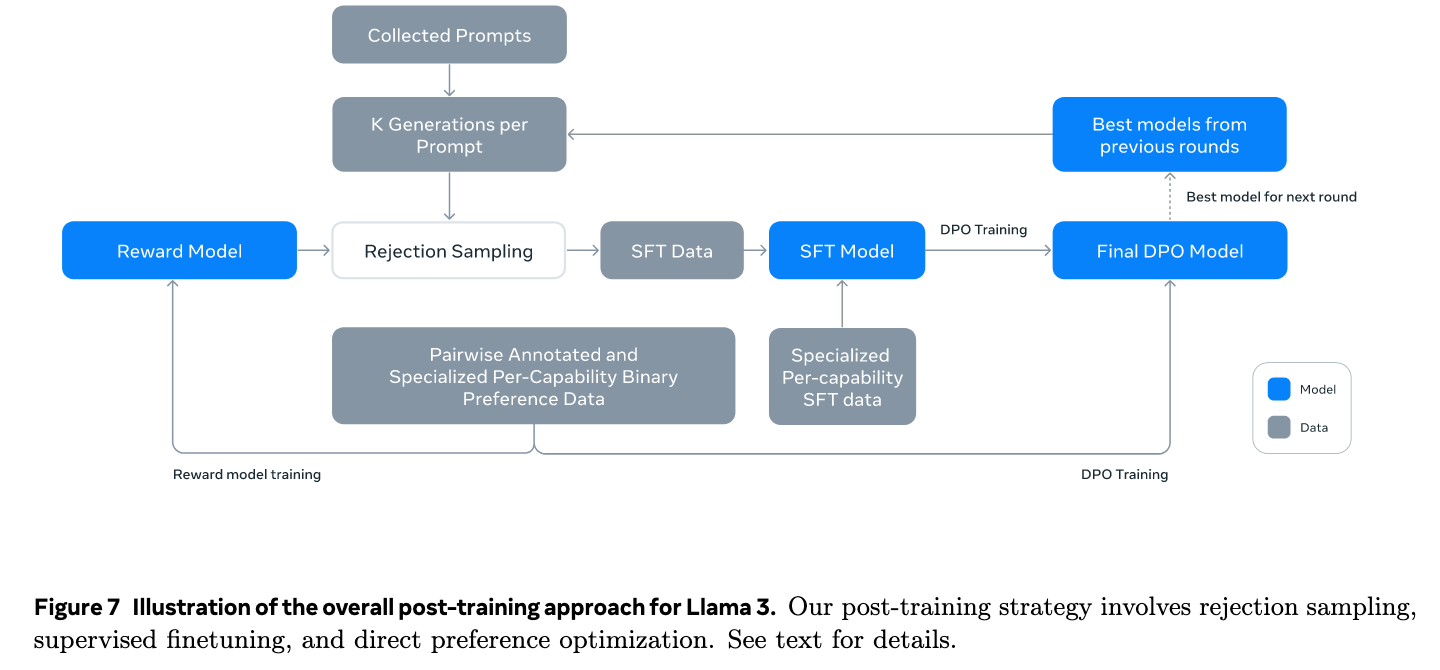
Llama3的post training每一轮中都是一个SFT跟着一个DPO,对应的训练数据来自于人工标记和模型生成;
Modeling
Llama 3后训练方法是迭代式的,总共做了6轮。每轮的核心操作是:Reward Modeling,Rejection Sampling,SFT,DPO。每个RM、SFT或DPO阶段,使用对不同的data mix或超参数进行实验所获得的模型进行加权平均。
Chat Dialog Format
问题5:为什么后训练的 LLM 需要 chat template?
chat template链接里面首先是一些用于标注prompt起始、对话角色、tool call的标志,这些token主要是为了让模型理解对话中人和AI谁在说话,以及工具调用到底返回了什么,毕竟后训练需要在对话和工具调用这种人机交互场景的prompt上微调,让LLM能够理解并合理回复用户的指令。
后面还有一些用于对齐的对话和工具调用的prompt-response模板,这些prompt和response就是用作输入指导模型学会和回复指令的。
问题5结束
问题6:根据 4.1 和 4.2 节,reward model 在整个后训练过程中起到什么作用?**
Reward Modeling
Reward Model 是用于拟合人类偏好,来给 LLM 做出反馈的。对于 LLM 的回复,RM 会进行打分,这个打分反映了生成回复符合人类偏好的程度,RM的结构往往就是在LLM上加了一个输出打分的隐藏层。
在Llama3中,RM是在预训练模型基础上训练的,训练的数据除了标准的(chosen,rejected)偏好对响应之外,还针对某些prompt创建了一个第三种“edited response”,也就是被人为修改的chosen response。每个样本都有两个或三个response,ranking是(edited > chosen > rejected )。在训练时,将prompt和随机打乱的response拼接起来输入,这和单独一个response计算分数是等效的,但是效率更高。训练的过程中模型会通过最大化 chosen_example、edited example 和 rejected_example 的标量得分差异来计算 loss,通过反向传播完成训练。
Supervised Finetuning
SFT就是即我们训练的输入是各种类型的指令,而需要模型拟合的输出则是我们希望模型在收到该指令后做出的回复。SFT要求模型对指令进行理解和回复,而不是简单地预测下一个 token,所以模型预测的结果不仅是 output,而应该是 input + output,只不过通过mask遮蔽 input 部分不参与 loss 的计算,但回复指令本身还是以预测下一个 token 的形式来实现的。
Direct Preference Optimization
参考资料:《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》
我们知道,一般在SFT后还会引入RLHF,类似于老师,让经过预训练学会基础知识和SFT学会解题方法的LLM学生解题,然后通过RLHF对输出的打分优化自己,不断提高分数强化正确的解题方式。SFT可以说类似“授人以鱼”,DPO就是”授人以渔“。
但是DPO通过数学推导把原本的强化学习过程简化为优化一个简单的loss,从而只要复制一个SFT模型不变,另一个模型用于迭代,通过计算loss反向传播就可以直接更新模型参数,实现原来RLHF的效果:
这个loss的梯度是:
可以看到结果是让模型更加偏向我们期望的输出。
在llama3中,每次DPO输入的preference data主要是由每轮被迭代的最强模型生成的,所以分布比较接近,更有利于训练。
同时还有一些改进,比如:
- 把前面引入的特殊的格式token给掩码掉,避免这些既在正面回答又在反面回答出现的token在训练中引起问题;
- 在原始 DPO 损失的基础上,额外添加一个监督学习式的 NLL 损失项:
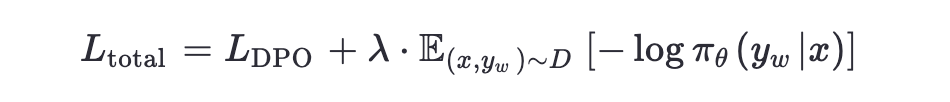
DPO 训练中添加 NLL 损失项以稳定模型生成格式
这个NLL loss只作用于chosen response,用来进一步稳定DPO训练,通过保持期望的生成格式,防止所选响应的对数概率下降。
Post-training data
这边写的有点乱,所以不按论文顺序整理了:
数据从哪里来?
- Preference Data:(标注人类偏好)
- Prompts:
人工编写、搜集的prompts;
随着模型改进不断提高prompt复杂程度; - 生成Response:
用多个不同数据配比和对齐方法训练模型,针对每个prompt选取两个不同的模型进行采样,生成两个response; - 生成数据:
人工对responses进行edit/chosen/reject标注,并注明chosen相对于reject是更好的程度,只选择那些显著好的样本用于训练。
用于训练RM:所有的preference data
用于训练DPO:最新一轮的preference data
- Prompts:
- SFT Data:(提供标准解法)
- Prompts:
人工编写、搜集的prompts;
在后训练迭代后期会引入特殊的system prompts,用来加强特定任务上的format、style等;
针对长文本,用预训练的Llama3生成QA对; - 生成Response:
上一轮DPO后的最佳模型:根据每个prompt生成K个response;
针对特定能力训练的expert模型:根据特别设计的prompt生成针对特定能力的synthetic data (specialized per-capability data); - 生成数据:
用Preference Data训练的RM对DPO后的response做rejection sampling,选择最好的response作为SFT Data;
经过rejection sampling的synthetic data;
少量人工标注数据;
- Prompts:
数据怎么处理的?
对一些不想要的回复模式去重;主题分类、质量评分、难度评分、roberta语义去重;
Reward Model的作用是什么?——Rejection Sampling
总结前面说的,Reward Model可以拟合到人类的偏好,所以后训练中,我们有包含偏好的preference data训练reward model,通过reward model对上一轮模型和特殊领域模型生成的SFT数据作rejection sampling,从而筛选出更符合我们偏好的SFT数据给模型学习,来让模型更加对齐人类偏好。
问题6结束
Inference
这一段主要是针对推理效率优化的内容。
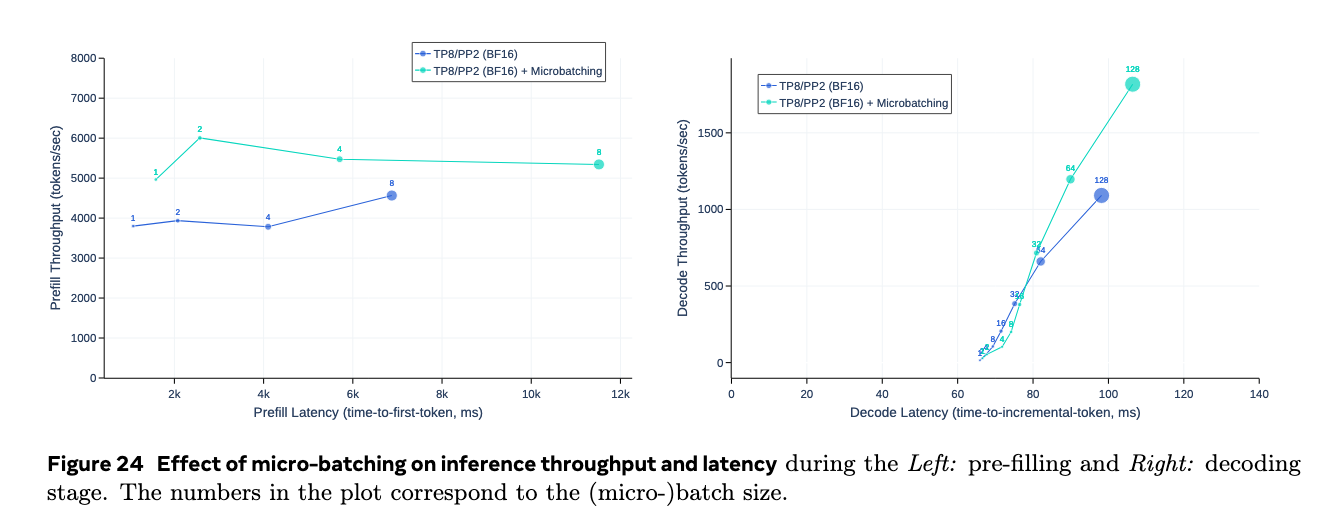
流水线并行
原始的BF16的405B模型无法放到一个推理machine上,所以采用并行放到两个推理设备上。用Tensor并行的瓶颈再与连接带宽和延迟,所以用流水线并行。
与训练不同,由于不需要反向传播,所以bubble效率问题不大,就分了micro-batch进行推理。
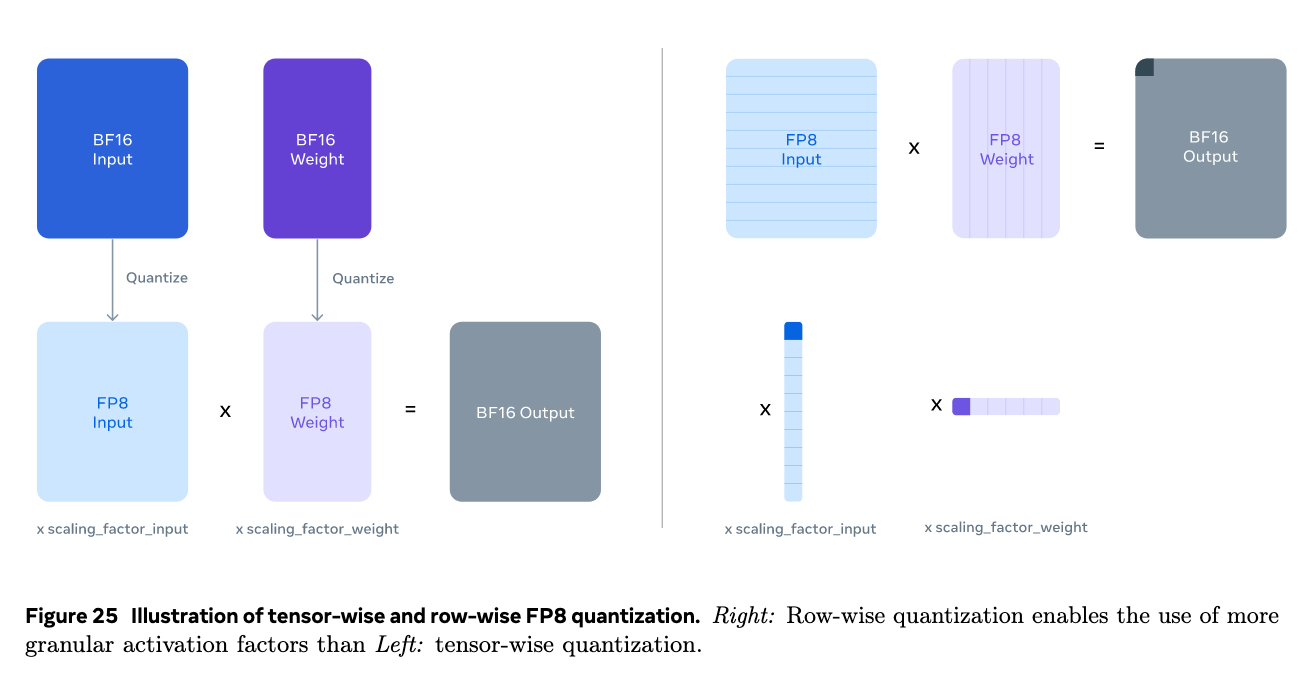
FP8量化
将模型参数量化为FP8降低显存占用,主要量化的是MLP中的参数,self-attention没有动。在量化的时候,保留了输入输出的transformer layer,并且采用了更精细的row-wise量化(逐行计算缩放参数)。
多模态扩展
Vision
数据
image的encoder和adapter用文本图像对训练,获取数据的时候需要四个主要阶段:(1)质量过滤,(2)感知去重(使用SSCD模型计算一个512维度的表示,用这些嵌入对数据集中的每个图像进行最近邻(NN)搜索,使用余弦相似度度量),(3)重采样(根据n-gram,(4)光学字符识别(通过OCR将图像中的文字拼接到caption中,有利于提升模型OCR能力);
在数据退火的时候还加入了带bounding box的image,截图,模型生成的图片等。同时还用了video-文本对。
模型架构
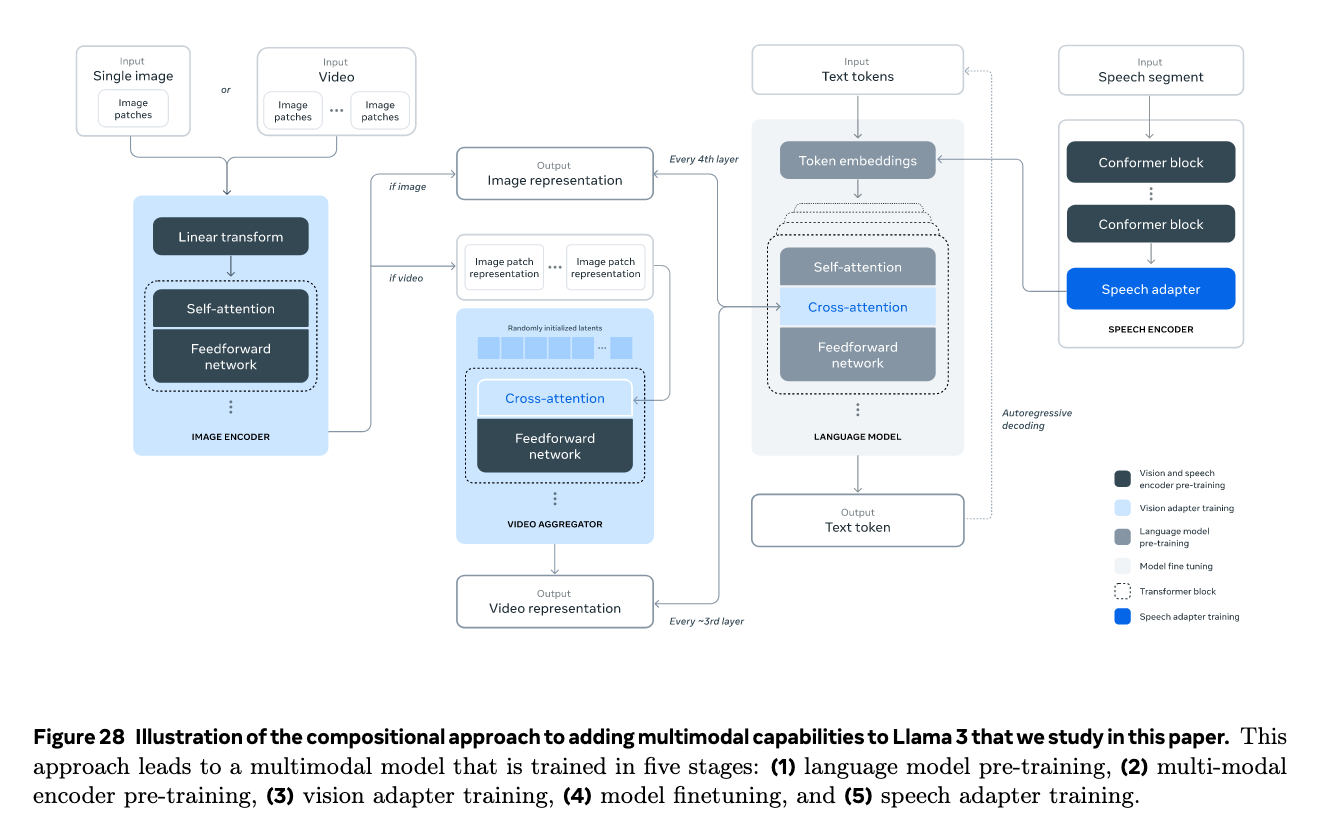
Image encoder: 标准的ViT,针对ViT难以捕捉细节的问题,提取了ViT中多层的输出加到最后一层输出中。此外,在交叉注意力层预训练之前进一步插入了8个门控自注意力层(总共40 transformer block),以学习对齐特定的特征。
image adapter:
在图像编码器生成的视觉token表示和语言模型生成的语言token表示之间引入了交叉注意层,实现图像和语言的融合。交叉注意层在核心语言模型中的每4个自注意层之后应用,与语言模型本身一样,交叉注意层使用广义查询注意(GQA)以提高效率。
在两个阶段对交叉注意力层的图像适配器进行预训练:
- 预训练
在约6B 图像-文本对的数据集上对图像适配器进行预训练; - 退火
继续在上述描述的退火数据集中的约500M 图像上训练图像适配器,进一步提高图像分辨率,以提高在需要高分辨率图像的任务上的性能。
video adapter:
模型最多可以输入64帧,每帧都由图像编码器处理。通过添加视频聚合器和交叉注意层对视频中的时间结构建模,先经过聚合器聚合,然后再输入交叉注意力层。
- 时间聚合器:
32个encoded的连续帧由时间聚合器聚合为一个帧输入,时间聚合器为perceiver resampler,perceiver resampler在预训练时每个视频使用16帧(聚合为1帧),但在监督微调期间将输入帧数增加到64帧; - 交叉注意力:
在每4个图像交叉注意层之前添加额外的视频交叉注意层。
将视觉识别组件添加到Llama 3之后,现在的模型包含自注意层、交叉注意层(包含图像交叉注意层和视频交叉注意层),和一个ViT图像编码器。
模型并行
主要用了流水线并行,通过确保每个流水线阶段包含五层来解决交叉注意力层运算量跟self-attention不平衡的问题:即语言主干中的四个自注意力层和一个交叉注意力层(回想一下,我们在每四个自注意力层之后引入一个交叉注意力层)
模型微调
图像SFT
语言模型的权重保持冻结状态以维持仅文本的性能,只更新视觉编码器和图像适配器的权重;
作者使用多个随机SFT数据子集、学习率和权重衰减值进行超参数搜索,根据不同参数模型的性能对其进行排名,对排名前K的模型的权重进行平均,以获得最终模型。 K的值通过评估平均模型并选择性能最高的实例来确定。
视频SFT
方法类似图像SFT,在这个阶段,将视频长度增加到64帧,并使用32的聚合因子来获得两个有效帧。 块的分辨率也增加了,以与相应的图像超参数保持一致。
DPO
与始终冻结参考模型相比,每k步以指数移动平均(EMA)方式更新ref model有助于模型从数据中学习更多,从而在人类评估中实现更好的性能。
Speech
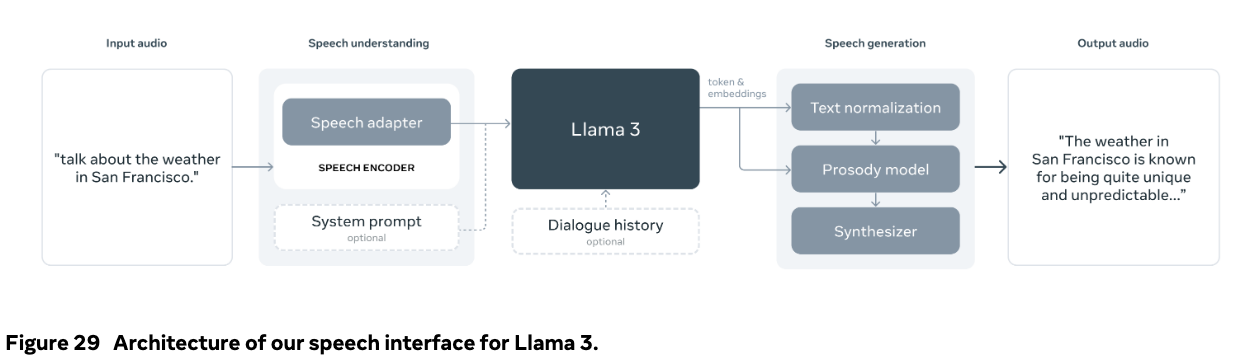
模型设计
这个模型包含两大块功能,speech理解和生成。语音模块的输出直接作为token表示输入到语言模型中,从而实现语音和文本标记之间的直接交互。语音模块与视觉模块有很大不同,后者通过交叉注意力层将多模态信息输入到语言模型中。 相比之下,语音模块生成的嵌入可以无缝集成到文本token中,使语音接口能够利用Llama 3语言模型的所有功能。
在输入端,结合了编码器和适配器来处理语音信号。利用系统提示(文本形式)来启用Llama 3在语音理解中的不同操作模式。 如果没有提供系统提示,模型将作为通用的口语对话模型,能够有效地以与Llama 3文本版本一致的方式响应用户的语音。
对话历史被引入作为提示前缀,以改善多轮对话体验,作者还尝试了启用Llama 3用于自动语音识别(ASR)和自动语音翻译(AST)的系统提示。
作者还尝试了一种语音生成方法,在这种方法中,实现了一个流式文本到语音(TTS)系统,该系统在语言模型解码过程中实时生成语音波形。他们基于专有的TTS系统设计了Llama 3的语音生成器,并且没有对语言模型进行语音生成的微调。 相反,他们通过在推理时利用Llama 3的嵌入来专注于提高语音合成的延迟、准确性和自然性。
语音理解
Speech encoder:
一个具有1B参数的Conformer模型。 模型的输入由80维的梅尔频谱图特征组成,这些特征首先由一个步幅为4的堆叠层处理,然后通过线性投影将帧长度减少到40毫秒;
处理后的特征由一个包含24个Conformer层的编码器处理,每个Conformer层具有1536的潜在维度,由两个4096维度的Macron-net前馈网络、一个核大小为7的卷积模块和一个具有24个注意力头的旋转注意力模块组成。
Speech adapter:
语音适配器包含大约1亿个参数。 由一个卷积层、一个旋转Transformer层和一个线性层组成。 卷积层的核大小为3,步幅为2,旨在将语音帧长度减少到80毫秒。 这使得模型能够为语言模型提供更粗粒度的特征。Transformer层具有3072的潜在维度和一个4096维度的前馈网络,在卷积下采样后进一步处理带有上下文的语音信息。 最后,线性层将输出维度映射到与语言模型嵌入层匹配。
语音生成
在Llama 3的语音生成系统中,Llama 3 8B的嵌入向量被应用于文本归一化(TN)和韵律建模(PM)两大核心环节。
TN模块利用LSTM模型和Llama 3的嵌入向量,通过交叉注意力机制实现上下文感知的书面语到口语context的流式转换,确保语义准确性;
PM模块则是一个单向Transformer模型,它通过双重交叉注意力机制分别融合来自TN的语音学特征和Llama 3的嵌入向量,以此在标记级别上精准预测音素的时长、基频和能量等韵律特征,从而在无需显式对齐的情况下显著提升合成语音的自然度、表现力并降低延迟,实现了准确且流畅的端到端语音合成。
模型训练
语音理解
Llama 3的语音理解能力通过一个两阶段的组合式方法构建,首先使用BEST-RQ算法在1500万小时的多语言语音数据上对语音编码器进行自监督预训练,使其具备跨语言和声学条件的强泛化能力;
随后,在监督微调阶段,将该编码器与一个专用的适配器一起,与冻结的Llama 3大语言模型联合训练,训练数据涵盖ASR、AST和口语对话,从而解锁了特定的语音理解功能。为了平衡语言特异性性能与模型通用性,llama3创新性地仅在系统提示中为输出文本指定目标语言(如“Repeat after me in English:”或“Translate into French:”),而不在输入语音端强制要求语言标识,这种设计不仅有效引导模型产生期望语言的响应,还保留了其在未见语言方向上的零样本迁移能力和处理语码转换语音的潜力,最终实现了强大且灵活的多语言语音交互。
语音生成
Llama 3的语音生成系统通过一个基于Transformer的韵律模型(PM)来提升合成语音的自然度和表现力,该模型将冻结的Llama 3 8B模型的嵌入向量作为关键输入。为实现低延迟的实时处理,系统采用了一种前瞻机制:对音素(phones)使用固定数量的未来信息前瞻,而对文本标记(tokens)则使用可变数量的前瞻,这种设计与文本归一化阶段的分块(chunking)过程相匹配。
训练时,该模型使用1,024个话语的批次大小,共进行100万次更新,初始学习率为9e-4,并采用AdamW优化器和余弦退火学习率调度,在前3,000次更新中进行学习率预热。
在推理阶段,系统严格遵循训练时的前瞻机制和因果掩码策略,以流式方式处理输入文本,确保了训练与部署的一致性。此外,为了增强长距离韵律依赖的建模能力,系统采用了delayed pattern approach,从而在保证低延迟的同时,显著提升了合成语音的自然度和表达质量。